“Softline, data-driven organization’s driving force”
- Softline is a group of data experts who can design, implement, and operate data systems.
- Since its origin, Softline has been in data business, and our expertise allows us to anticipate what is to come and what needs to be done.
- Softline understands enterprise data systems in various industries better than anyone else and knows required qualities to become data-driven.
- Out market-proven data engineering and data science expertise will help your journey toward data-driven organization.
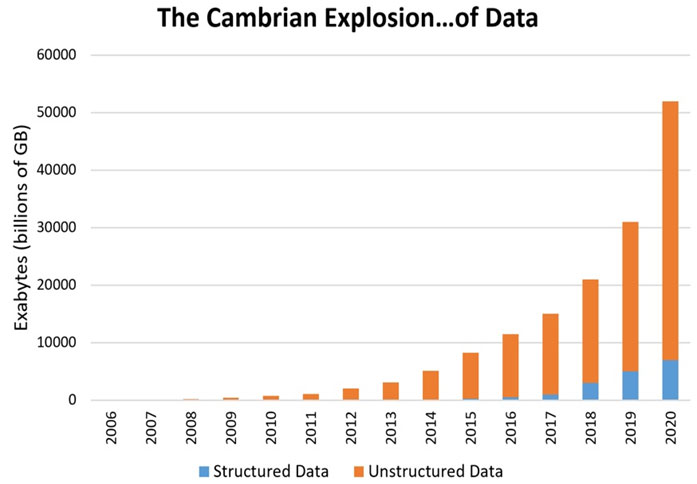
21st Century is Big Data Era
Volume and variety of digital data are exploding due to increasing number of digital services, devices, and sensors. IDC predicts digital data to be increased by 42% yearly until 2020. Hal Varian, chief economist at Google, says the volume of digital data will expand by more than 50 times between 2010 and 2020.
“"Between the dawn of civilization and 2003, we only created five exabytes; now we're creating that amount every two days. By 2020, that figure is predicted to sit at 53 zettabytes (53 trillion gigabytes) -- an increase of 50 times.” - Hal Varian, Chief Economist at Google
“"Between the dawn of civilization and 2003, we only created five exabytes; now we're creating that amount every two days. By 2020, that figure is predicted to sit at 53 zettabytes (53 trillion gigabytes) -- an increase of 50 times.” - Hal Varian, Chief Economist at Google
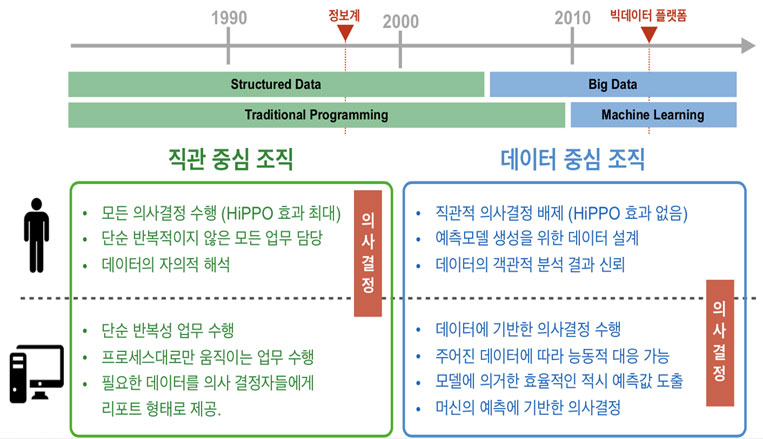
Data-Driven Organization
Almost all organizations equipped with differential competitive advantage in Big Data era are data-driven organizations. An MIT report released in 2011 (Strength in Numbers : How Does Data-Driven Decision-making Affect Firm Performance?) showed that general productivity of data-driven organization is 5-6% higher than industry average.
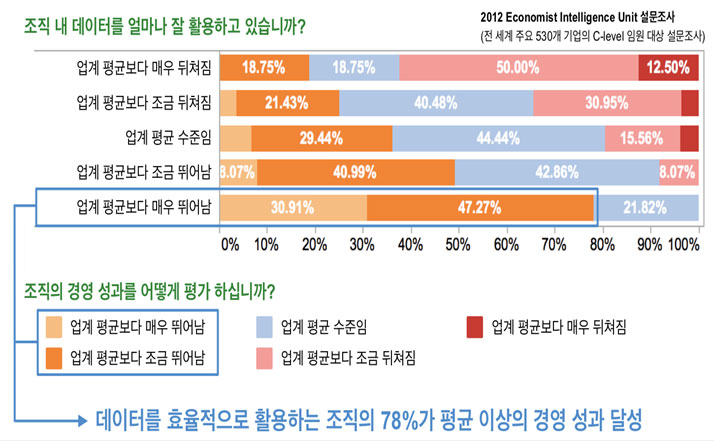
One survey from The Economist revealed that 78% of companies that regarded themselves as data leader achieved beyond average performance in respective industry.
What is data-driven organization then? An organization operating on a lot of reports? An organization which invested a hefty sum of budget to set up Hadoop or ML platforms?
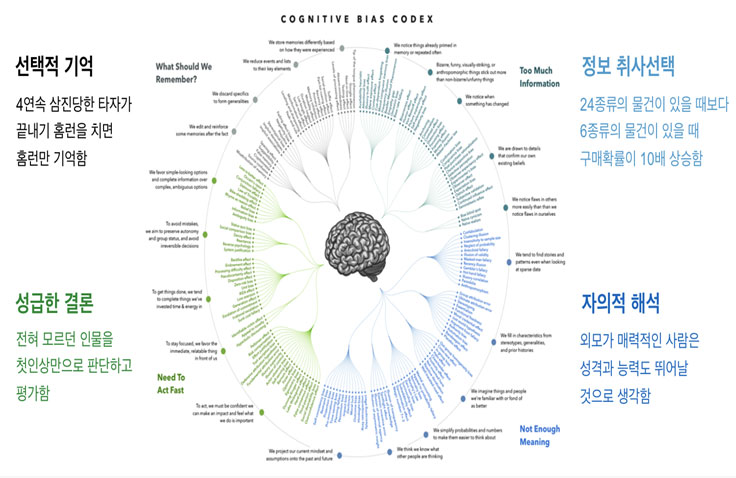
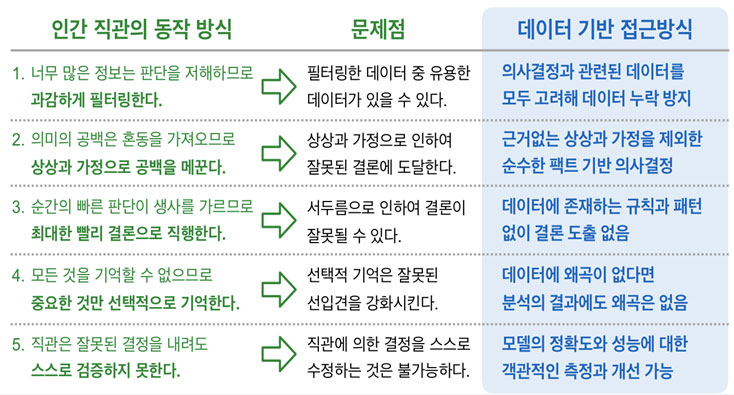
Why does data-driven decision making matter? Because human intuition is faulty especially in objectivity.
One survey from The Economist revealed that 78% of companies that regarded themselves as data leader achieved beyond average performance in respective industry.
What is data-driven organization then? An organization operating on a lot of reports? An organization which invested a hefty sum of budget to set up Hadoop or ML platforms?
Why does data-driven decision making matter? Because human intuition is faulty especially in objectivity.
1. Data-Driven Culture
In data-driven organizations, there is a wide belief that data is more trustworthy than intuition. The more members share this perspective, the closer an organization approaches to be data-driven. This is not an easy nor a short-haul task. It requires a stern internal organizational commitment to drive constant change management. No outsiders can do that for you.
2. Data EngineeringWithout proper infrastructure, digital data cannot be utilized. To have that infra, you need data engineering. It is a series of technological activities to collect, unify, cleanse, distribute, and safely guard data asset in a given organization. Data engineering is a pre-requisite for down stream analysis where fancy things like machine learning and AI are happening.
Softline has been in data engineering business since its origin and accumulated know-how about design, implementation, and operation of data infrastructure.
3. Data ScienceOftentimes, data science, machine learning, and AI are synonymized or used interchangeably. But these three are not the same (Refer to ‘Data Science’ section for more detail). AI is an outcome of data science, and machine learning is an analysis methodology for data scientists. Even though there are diverse interpretation of data science, here we define it as a line of activities to analyze data, find statistically meaningful patterns, draw actionable insights, persuade others to buy in its findings, and help others to deploy its findings within business process.
Softline has implemented and operated a number of analytics systems using market-proven solutions such as MSTR and Vertica.