Background of Data Storage (from SMP to MPP)
Since the birth of computer, storing data reliably and cost-efficiently has been a major issue. Until late 1990s, the only viable solution to this issue was high-power pricey storages. But as Big Data era opens up, existing solutions began to show critical shortcomings due to data explosion and complex data demand.
The biggest problem was cost. As more and more applications implemented, related digital data was increasing exponentially. Naturally, cost for additional or new storage systems took up too much portion of IT budget. Once promoted thin provisioning based on storage virtualization was only a stop-gap measure.
The second issue was performance, especially high-throughput required for massive data processing. Solutions like increasing network bandwidth between storage layer and server layer or high disk I/O in storage layer could not solve the fundamental structural problem, data bottleneck at centralized storage.
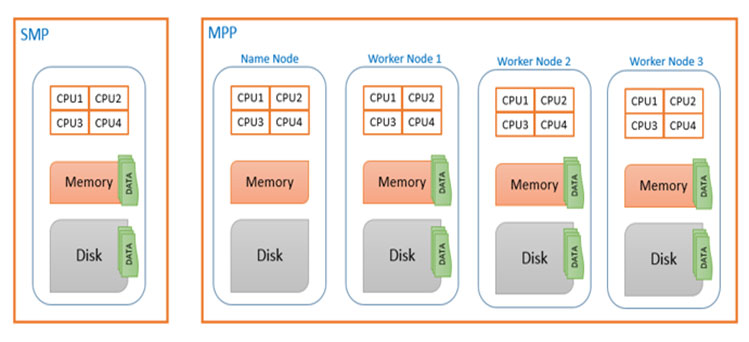
An architecture where multiple application servers are connected to a single storage is called SMP (Symmetric Multi-Processing). SMP architecture depends majorly on ‘scale-up’ when capacity or performance needs to be upgraded. But ‘scale-up’ involves high cost and does not solve the bottleneck problem all the same.
Things began to change in late 1990s when new dot-com companies began to arise. Under heavy pressure to store and process massive data with limited budget, they needed an alternative to overcome fundamental drawbacks of SMP. Their answer was to distribute centralized data to multiple servers in a cluster and to let each server to process locally stored small data in parallel. This architecture was widely more performant than SMP in massive data storing and processing both in cost and performance. Also it can easily adopt ‘scale-out’ approach using commercial hardwares for data increase and performance enhancement providing flexibility and cost efficiency. This new distributed parallel architecture is called MPP (Massive Parallel Processing).
The biggest problem was cost. As more and more applications implemented, related digital data was increasing exponentially. Naturally, cost for additional or new storage systems took up too much portion of IT budget. Once promoted thin provisioning based on storage virtualization was only a stop-gap measure.
The second issue was performance, especially high-throughput required for massive data processing. Solutions like increasing network bandwidth between storage layer and server layer or high disk I/O in storage layer could not solve the fundamental structural problem, data bottleneck at centralized storage.
An architecture where multiple application servers are connected to a single storage is called SMP (Symmetric Multi-Processing). SMP architecture depends majorly on ‘scale-up’ when capacity or performance needs to be upgraded. But ‘scale-up’ involves high cost and does not solve the bottleneck problem all the same.
Things began to change in late 1990s when new dot-com companies began to arise. Under heavy pressure to store and process massive data with limited budget, they needed an alternative to overcome fundamental drawbacks of SMP. Their answer was to distribute centralized data to multiple servers in a cluster and to let each server to process locally stored small data in parallel. This architecture was widely more performant than SMP in massive data storing and processing both in cost and performance. Also it can easily adopt ‘scale-out’ approach using commercial hardwares for data increase and performance enhancement providing flexibility and cost efficiency. This new distributed parallel architecture is called MPP (Massive Parallel Processing).
MPP Prime Time
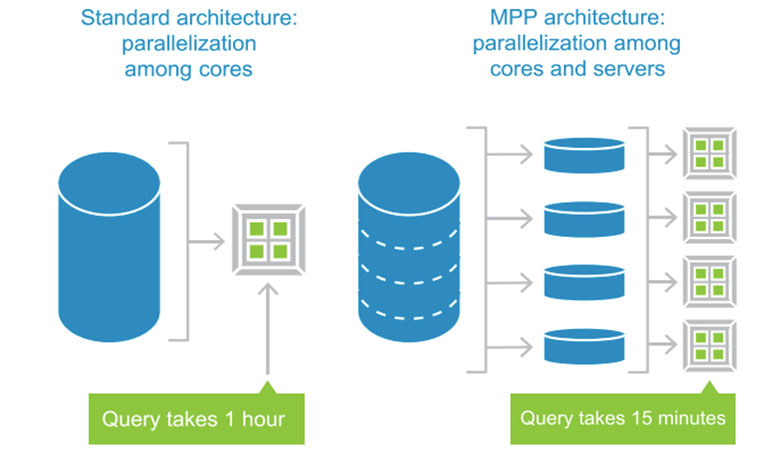
MPP has become de-facto standard of data systems in Big Data era. Not only cost-efficiency in data storing, but also query performance to high-volume data is far superior to SMP. Why? Let’s say there is a task to count the total number of ‘data’ in a 10 book set encyclopedia. If one Harvard graduate majored in applied mathematics and 10 fifth graders compete each other who finishes the task first, who do you think is likely to win? The former must go through the entire 10 books and do simple counting where his extensive knowledge in math and statistics are useless. By the way, each member of the latter group needs to check only one book. Naturally, the latter wins despite the former’s high-level education. In the same sense, MPP is much superior to SMP in massive data processing.
SSOT and MVOT
MPP is not the whole story. Data storages with cost-efficiency and performance is a starting point. The real challenge is how to design them in order to minimize data isolation and duplication, to maintain data consistency, and to meet downstream users’ requirements. These are not only related to data storage but all other data engineering activities, but we would like to mention them here.
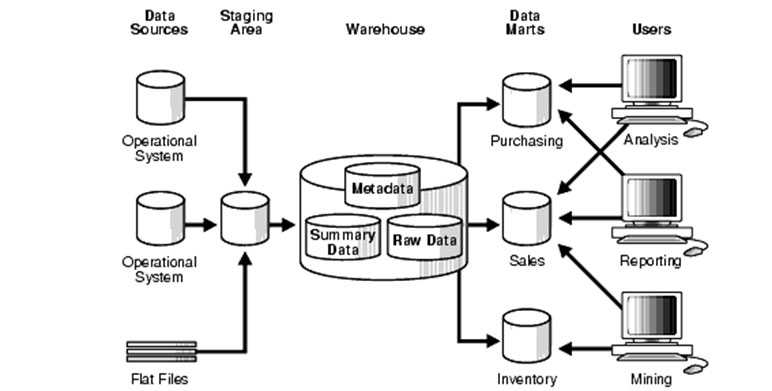
Basic strategy of data storage is to find the balance between two contradicting views. These are SSOT (Single Source of Truth) and MVOT (Multiple Versions of Truth). SSOT is to maintain consistency. It prevents incorrect data from being circulated by keeping the original data. MVOT is the opposite approach where data is stored in multiple locations so as to meet data requirement from each department. Simply put, data warehouse is SSOT, and data mart is MVOT.
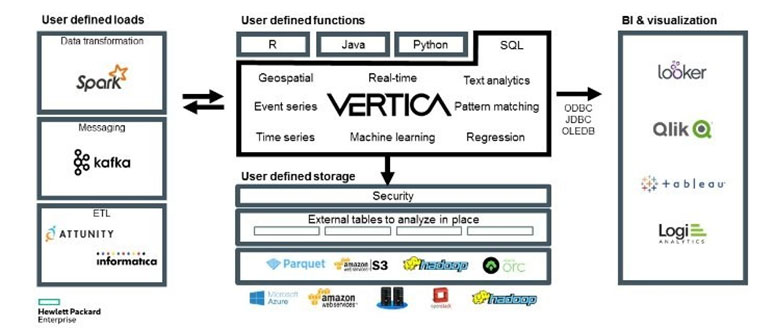
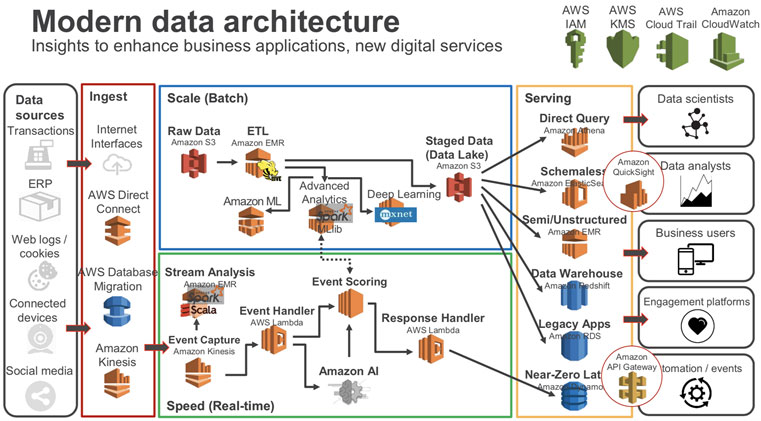
This is where EDW (Enterprise Data Warehouse) and data lake comes in. Both are ultimate SSOTs, to put it simply. As the boundary between SSOT and MVOT gets blurred and many existing data warehouses fail to play SSOT role, the alternative was to build a new layer, the first destination of all data. The remaining data storages are considered to be MVOTs generated from one single SSOT layer. This is the basic concept of many big data platform including commercial cloud service provider like Amazon and Google. Refer to the high-level architecture of AWS data architecture.
Basic strategy of data storage is to find the balance between two contradicting views. These are SSOT (Single Source of Truth) and MVOT (Multiple Versions of Truth). SSOT is to maintain consistency. It prevents incorrect data from being circulated by keeping the original data. MVOT is the opposite approach where data is stored in multiple locations so as to meet data requirement from each department. Simply put, data warehouse is SSOT, and data mart is MVOT.
This is where EDW (Enterprise Data Warehouse) and data lake comes in. Both are ultimate SSOTs, to put it simply. As the boundary between SSOT and MVOT gets blurred and many existing data warehouses fail to play SSOT role, the alternative was to build a new layer, the first destination of all data. The remaining data storages are considered to be MVOTs generated from one single SSOT layer. This is the basic concept of many big data platform including commercial cloud service provider like Amazon and Google. Refer to the high-level architecture of AWS data architecture.
Compatibility
As a central piece of bigger platform, all data storages must be compatible with other parts of the platform such as upstream data ingestion and preparation tools, downstream analysis and visualization tools, and other fellow data storages. If not, they become isolated data silos, which organizations must avoid to have because data becomes strategic asset only when they are well-circulated and well-enriched.