Data Quality is Key
What is the most important quality for a big data platform? Hadoop? Machine learning? AI? All of these are optional. The most essential requirement is high quality data. Even though most of attention goes to ML and AI, they are useless without quality data. The fact that multiple studies show most data scientists spend 80% of their time in data extraction and preparation clearly indicates how important data quality is. If data is incorrect, incomplete, ambiguous, unanalyzable, or untimely, data volume does not matter.
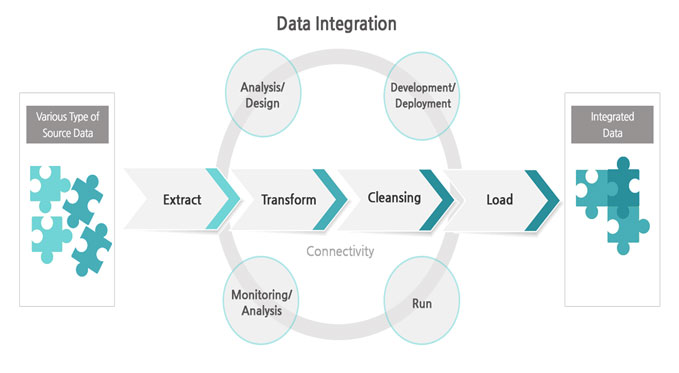
Data is messy in its nature. Errors in data can be created at any point in data pipeline : creation, transmission, storage, processing, and consumption. Therefore, data from source must be cleansed and transformed when it is loaded for analytics purpose. A series of activities to cleanse and transform is data unification and preparation.
Data is messy in its nature. Errors in data can be created at any point in data pipeline : creation, transmission, storage, processing, and consumption. Therefore, data from source must be cleansed and transformed when it is loaded for analytics purpose. A series of activities to cleanse and transform is data unification and preparation.
Acquiring High-quality Data
There are several criteria for high quality data.
The goal of data unification and preparation is to unify and transform low-quality source data into high-quality data that meets the above criteria.
Data unification means creating unified dataset by merging multiple sources of data for downstream consumption. You can come up with schema for unified dataset either top-down & deterministic way or bottom-up & probabilistic way.
Data preparation is to escalate the quality of data by formatting, deleting missing values, adding delimiters, de-duplicating records, handling outliers, etc.
1. Accessible : Data consumers should be able to easily access and extract necessary data.
2. Accurate : Data must be correctly representing reality.
3. Coherent : Data must be coherently joinable to other with other data.
4. Complete : Data must not contain missing values.
5. Consistent : Same data must maintain same format in all places.
6. Defined : Data must be clearly defined and unambiguous.
7. Relevant : Data must be related to downstream data analysis.
8. Reliable : Data must be reliably acquired via stable pipeline.
9. Timely : Data must be acquired and analyzed on time.
2. Accurate : Data must be correctly representing reality.
3. Coherent : Data must be coherently joinable to other with other data.
4. Complete : Data must not contain missing values.
5. Consistent : Same data must maintain same format in all places.
6. Defined : Data must be clearly defined and unambiguous.
7. Relevant : Data must be related to downstream data analysis.
8. Reliable : Data must be reliably acquired via stable pipeline.
9. Timely : Data must be acquired and analyzed on time.
The goal of data unification and preparation is to unify and transform low-quality source data into high-quality data that meets the above criteria.
Data unification means creating unified dataset by merging multiple sources of data for downstream consumption. You can come up with schema for unified dataset either top-down & deterministic way or bottom-up & probabilistic way.
Data preparation is to escalate the quality of data by formatting, deleting missing values, adding delimiters, de-duplicating records, handling outliers, etc.
Batch vs Streaming
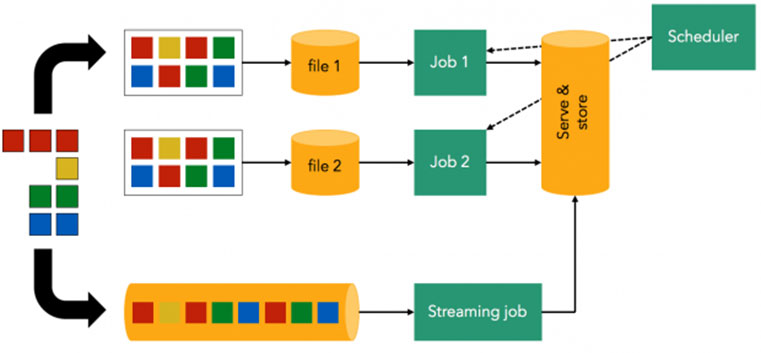
One of hte most important factor to consider at this stage is the type of data ingestion. There are two types in terms of data ingestion; bounded and unbounded.
Bounded data has clear temporal border in data ingestion. For example, daily batch loading job loads data that has been accumulated during the last 24 hours. In this case, every loaded data has boundary of 24 hours, hence bounded data. Since bounded data is the result of accumulation during a given time, batch processing is an appropriate choice and ETL (Extract, Transform, Load) is the most well-known technology for it.
Benefits of Batch Processing
Drawback of Batch Processing
Unbounded data, in contrast to bounded data, has no or very short temporal boundary. Since data is flowing in continuously, it needs to be processed upon arriving. This processing method is called streaming processing, and it is essential for real-time or near real-time data analysis. Data is inherently unbounded because it is created at any given moment at source level. Depending on analysis requirements, one should decide whether to set up short-term boundary in incoming data flow, or to process flowing data as it is. Micro-batch, which is adopted by Spark Streaming, is one of the well-known streaming processing. Also CEP (Complex Event Processing) is a widely known term, which is about aggregating and categorizing incoming data flow in meaningful units.
Benefits of Streaming Processing
Drawbacks of Streaming Processing
Bounded data has clear temporal border in data ingestion. For example, daily batch loading job loads data that has been accumulated during the last 24 hours. In this case, every loaded data has boundary of 24 hours, hence bounded data. Since bounded data is the result of accumulation during a given time, batch processing is an appropriate choice and ETL (Extract, Transform, Load) is the most well-known technology for it.
Benefits of Batch Processing
1. Completeness and consistency in data
2. Relatively simple and reliable
2. Relatively simple and reliable
Drawback of Batch Processing
1. Must wait until next batch for new data.
2. Regular dedicated hour, mostly during night time, for batch loading.
2. Regular dedicated hour, mostly during night time, for batch loading.
Unbounded data, in contrast to bounded data, has no or very short temporal boundary. Since data is flowing in continuously, it needs to be processed upon arriving. This processing method is called streaming processing, and it is essential for real-time or near real-time data analysis. Data is inherently unbounded because it is created at any given moment at source level. Depending on analysis requirements, one should decide whether to set up short-term boundary in incoming data flow, or to process flowing data as it is. Micro-batch, which is adopted by Spark Streaming, is one of the well-known streaming processing. Also CEP (Complex Event Processing) is a widely known term, which is about aggregating and categorizing incoming data flow in meaningful units.
Benefits of Streaming Processing
1. Low latency between data ingestion and analysis.
2. When properly designed, no more batch processing.
2. When properly designed, no more batch processing.
Drawbacks of Streaming Processing
1. Limited market awareness and technical understanding.
2. Far more complex than batch processing.
2. Far more complex than batch processing.
Top-down vs Bottom-up
Large organizations typically have a number of databases for a number of applications. This entails roughly two issues.
There are two approaches to handle these issues.
1. Duplicated unidentical data for same entity
2. Non-existent categorization
Each of decentralized databases has its own way to ingest, process, and store data, thus it is only natural multiple copies of data for the same entity differ. For example, sales team handles customer data alligned with order or revenue, while marketing team sees customer as a potential targets for marketing promotion. Because of this gap, same customer might be differently represented in sales and marketing. Under this circumstance, it can be hard to accurately figure out the exact number of customers.
2. Non-existent categorization
Having an organizational data map or taxonomy is a highly sought-after task, but it is a tall order since data always changes as business context changes. Many organizations depend on top-down approach by defining overarching taxonomy and forces deterministic rules to categorize data. But those rules may not apply to all data, and the defined taxonomy cannot last forever.
There are two approaches to handle these issues.
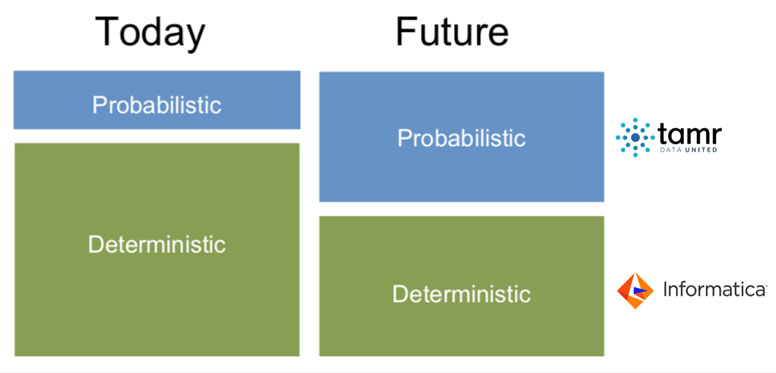
1. Top-down / deterministic
2. Bottom-up / probabilistic
These two approaches are not mutually exclusive but supportive. The former can set up high-level structure of organization’s data, and the latter can provide flexibility to the structure especially on the low-level structure.
Traditionally tried methods such as MDM (Master Data Management), metadata system are dependent on pre-defined schema and rules. In order to develop these pre-defined structure, organizations need to invest large amount of budget and time. While it is necessary to have a high-level data structure, it lacks flexibly to correctly represent ever-changing nature of data.
2. Bottom-up / probabilistic
A new way to compensate top-down approach is automated data curation using machine learning. It means one can develop unified schema, de-duplicated and categorized dataset by looking at data itself. This approach was not an option until recently because sifting through billions of records intelligently to do so. But now, machine learning can handle this task with the right and minimal human guidance. Tamr is a data curation tool to enable automated data curation by combining sophisticated machine learning algorithms and human expertise.
These two approaches are not mutually exclusive but supportive. The former can set up high-level structure of organization’s data, and the latter can provide flexibility to the structure especially on the low-level structure.
SOFTLINE
ADDRESS
SOFTLINE Co., Ltd.
2F~3F door, 3 Yonghyeon-ro, Dukyang-gu, Goyang-si, Gyeonggi-do, Korea
CONTACT US
Email : jhlee@softline.biz