Danger of Static Distribution
In any data system, data flows from source to consumer. If the number of sources are limited and consumer demands are relatively simple and unchallenging, static data distribution may not be a big issue. But things are rarely simple. Almost all applications have their own DBMS, daily business creates document files in various formats stored in departmental file servers, and IT devices generates a long line of log data every second. Data also comes from outside of an organization such as social media, search trend, customer survey.
Data consumers also have diverse requirements about which source data to use in what format, how to transform them, and how long they can tolerate latency. Under this circumstance, data from multiple sources gets collected, transformed, stored, and distributed to various consumers.
Data consumers also have diverse requirements about which source data to use in what format, how to transform them, and how long they can tolerate latency. Under this circumstance, data from multiple sources gets collected, transformed, stored, and distributed to various consumers.
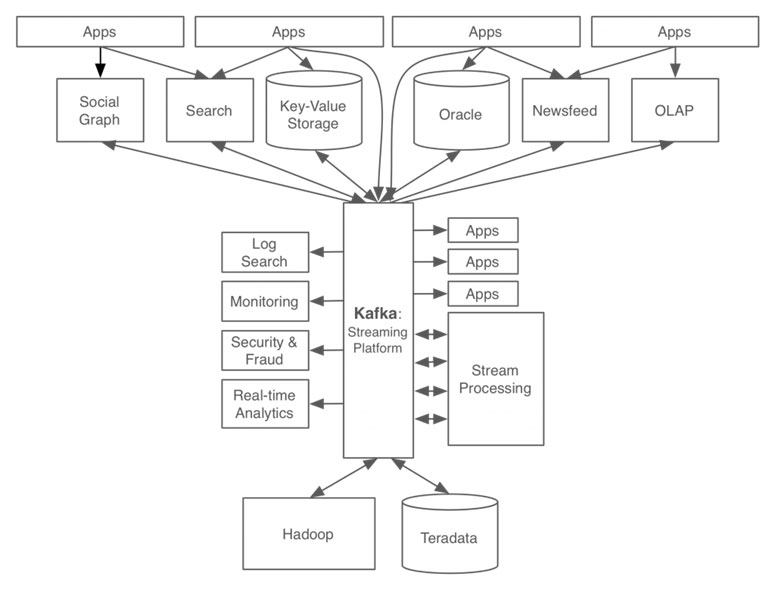
Data Hub
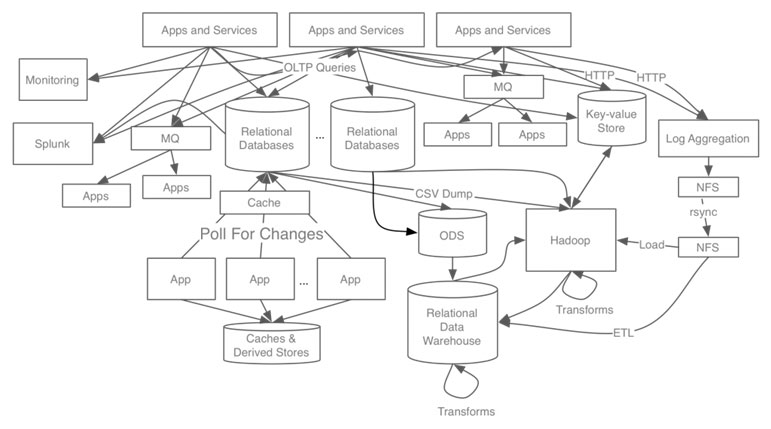
Handling these complicated data pipelines is called data plumbing. It takes the lion’s share of data engineer’s time and effort, and naturally engineer dependecy get very high. Sadly, no matter how much effort is invested, it is still extremely difficult to add flexibility to data distribution unless fundamental structural issue of N-to-N connection is resolved.
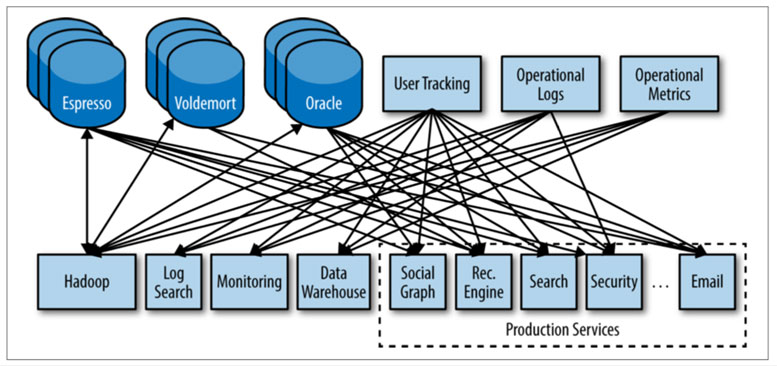
In N-to-N relation, data engineers have to consigure both ends of each pipeline separately. It is not hard to imagine their workload get easily balooned up as the number of producers or consumers increase (max N x N pipelines). Considering that both consumers and producers are consisted of heterogeneous systems, the level of compexity goes even higher.
On the other hand, in N-to-1-to-N relation, regardless of the number of producers and consumers, data engineers manage producers-to-hub and hub-to-consumers data pipelines, which can reduce their quantitive workload significantly (max N + N pipelines). This also lowers the hurdle qualititively because engineers do not have to make connections between two different systems. Plus, data hub provides an unified view over all data pipelines.
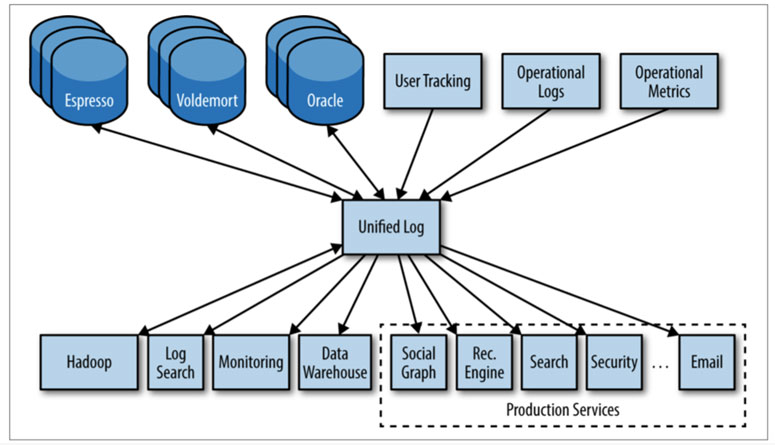
In N-to-N relation, data engineers have to consigure both ends of each pipeline separately. It is not hard to imagine their workload get easily balooned up as the number of producers or consumers increase (max N x N pipelines). Considering that both consumers and producers are consisted of heterogeneous systems, the level of compexity goes even higher.
On the other hand, in N-to-1-to-N relation, regardless of the number of producers and consumers, data engineers manage producers-to-hub and hub-to-consumers data pipelines, which can reduce their quantitive workload significantly (max N + N pipelines). This also lowers the hurdle qualititively because engineers do not have to make connections between two different systems. Plus, data hub provides an unified view over all data pipelines.
Transformation within Distribution Process
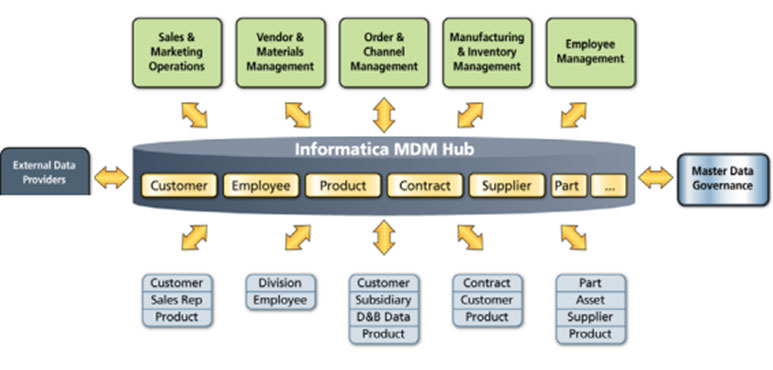
Data almost always is transformed for business purposes. Each consumer group is likely to create its own MVOT through its own transformation. If these MVOTs are rarely referenced each other, there are not much trouble. But if not, data for core entities like customer, revenue, cost, etc will differ and that will be a critical issue. Thus, these core entities must be represented in the same schema with same value (a.k.a. golden record) preferably in one place, in other words SSOT. When all other applications need these data, they do not make a copy but refer to the integrate storage. This is MDM (Master Data Management).
Privacy and Security
Privacy issue has been nothing but escalating for a long time, particularly in Big Data era where all kinds of data is abundant and needs for data is ever higher due to machine learning’s sky-high attention. The dark side of Big Data is that data can reveal more about a person than he or she intends to.
GDPR (General Data Protection Regulation) is one of the most popular privacy protection standard. EU developed it and it has been enacted since May 2018. The regulation is widely agreed to be the most comprehensive set of rules to protect privacy that other countries can follow with some modification, so being GDPR-compliant is now a good way to show commitment in data security. GDPR is comprehensive because it covers not just privacy, but also data leak and access. Thanks to all of the above, GDPR is now a de-facto standard for data protection regulation.
In order to minimize the penalty and damage stemmed from data breach, a number of organizations are hiring a new high-level staff position called DPO (Data Protection Officer). Legal team is now taking data security issue very seriously even hiring experts in this subject. For data engineers, data security is now an integral part of their work more than ever before.
GDPR (General Data Protection Regulation) is one of the most popular privacy protection standard. EU developed it and it has been enacted since May 2018. The regulation is widely agreed to be the most comprehensive set of rules to protect privacy that other countries can follow with some modification, so being GDPR-compliant is now a good way to show commitment in data security. GDPR is comprehensive because it covers not just privacy, but also data leak and access. Thanks to all of the above, GDPR is now a de-facto standard for data protection regulation.
In order to minimize the penalty and damage stemmed from data breach, a number of organizations are hiring a new high-level staff position called DPO (Data Protection Officer). Legal team is now taking data security issue very seriously even hiring experts in this subject. For data engineers, data security is now an integral part of their work more than ever before.
