ЧйНЩРК ЕЅРЬХЭ ЧАСњ
КђЕЅРЬХЭ ЧУЗЇЦћПЁ ЙнЕхНУ ПфБИЕЧДТ АЭРК ЙЋОљРЯБюПф? ЧЯЕг? ИгНХЗЏДз? AI? РЬ И№ЕЮДТ РжОюЕЕ ЕЧАэ ОјРИИщ БзИИРЮ ПфМвЕщРдДЯДй. И№Еч ЕЅРЬХЭ НУНКХлРЬ Р§ДыРћРИЗЮ АЎУпОюОп Чв АЁРх СпПфЧб ПфМвДТ ЙйЗЮ АэЧАСњРЧ ЕЅРЬХЭРдДЯДй. ИгНХЗЏДз БтЙнРЧ AIАЁ НУРхРЧ АќНЩРЛ ЕЖТїСіЧЯИщМ ДыКЮКаРЧ СЖСїЕщРЬ ЕЅРЬХЭ КаМЎ ПЕПЊПЁИИ ПТ НХАцРЛ С§СпЧЯАэ РжСіИИ ЛчНЧ АЁРх СпПфЧЯИщМЕЕ ЧЪМі КвАЁАсЧб ПфМвДТ ДйИЇОЦДб ЕЅРЬХЭ ЧАСњРдДЯДй. ИгНХЗЏДзРЛ ШАПыЧи ПЙУјИ№ЕЈРЛ ИИЕхДТ ЕЅРЬХЭ ЛчРЬО№ЦМНКЦЎЕщРЬ РлОїНУАЃРЧ 80% ИІ ЕЅРЬХЭ УпУт Йз СЄСІ РлОїПЁ ХѕРкЧЯАэ РжДйДТ КЙМіРЧ ПЌБИАсАњАЁ РЬИІ СѕИэЧеДЯДй. ЕЅРЬХЭАЁ СЄШЎЧЯСі ОЪАХГЊ, КаМЎЧв Мі ОјДТ ЧќХТРЬАХГЊ, ДЉЖєАЊРЬ ИЙАХГЊ, СпРЧРћРЬАХГЊ, РЬЙЬ РЏШПБтАЃРЬ СіГ ЕЅРЬХЭАЁ ДыКЮКаРЬЖѓИщ СІ ОЦЙЋИЎ ИЙРК ЕЅРЬХЭИІ КИРЏЧЯАэ РжДй ЧиЕЕ ШАПыАЁФЁДТ АХРЧ ОјДйАэ Чв Мі РжНРДЯДй.
ЧЯСіИИ ОШХИБѕАдЕЕ АХРЧ И№Еч ПјУЕ ЕЅРЬХЭДТ СіРњКаЧеДЯДй. ЕЅРЬХЭ Л§МК СжУМРЧ РхОж, РќМл ЛѓРЧ РхОж, РњРх ПРЗљ, РдЗТ ПРЗљ, УГИЎ Йз АќИЎ ПРЗљ, ЕЅРЬХЭ МГАш ПРЗљ Ею МіИЙРК ПјРЮЕщЗЮ РЮЧи ЕЅРЬХЭ НУНКХлРЧ ПјУЕ ЕЅРЬХЭДТ БтКЛРћРИЗЮ ЧАСњРЬ ИХПь ГЗДйАэ АЁСЄЧЯДТ ЦэРЬ ПЧНРДЯДй. БзЗИБт ЖЇЙЎПЁ ПјУЕ ЕЅРЬХЭИІ ДмМјШї МіС§ЧЯПЉ ЙйЗЮ ЕЅРЬХЭ НУНКХлПЁ РћРчЧиМДТ ОШЕЫДЯДй. РћРч РЬРќПЁ РЯЗУРЧ СЄСІ Йз КЏШЏРлОїРЛ АХУФОп ЧЯИч ЙйЗЮ РЬ РлОїРЬ ЕЅРЬХЭ ХыЧе Йз СЄСІ РдДЯДй.
ЧЯСіИИ ОШХИБѕАдЕЕ АХРЧ И№Еч ПјУЕ ЕЅРЬХЭДТ СіРњКаЧеДЯДй. ЕЅРЬХЭ Л§МК СжУМРЧ РхОж, РќМл ЛѓРЧ РхОж, РњРх ПРЗљ, РдЗТ ПРЗљ, УГИЎ Йз АќИЎ ПРЗљ, ЕЅРЬХЭ МГАш ПРЗљ Ею МіИЙРК ПјРЮЕщЗЮ РЮЧи ЕЅРЬХЭ НУНКХлРЧ ПјУЕ ЕЅРЬХЭДТ БтКЛРћРИЗЮ ЧАСњРЬ ИХПь ГЗДйАэ АЁСЄЧЯДТ ЦэРЬ ПЧНРДЯДй. БзЗИБт ЖЇЙЎПЁ ПјУЕ ЕЅРЬХЭИІ ДмМјШї МіС§ЧЯПЉ ЙйЗЮ ЕЅРЬХЭ НУНКХлПЁ РћРчЧиМДТ ОШЕЫДЯДй. РћРч РЬРќПЁ РЯЗУРЧ СЄСІ Йз КЏШЏРлОїРЛ АХУФОп ЧЯИч ЙйЗЮ РЬ РлОїРЬ ЕЅРЬХЭ ХыЧе Йз СЄСІ РдДЯДй.
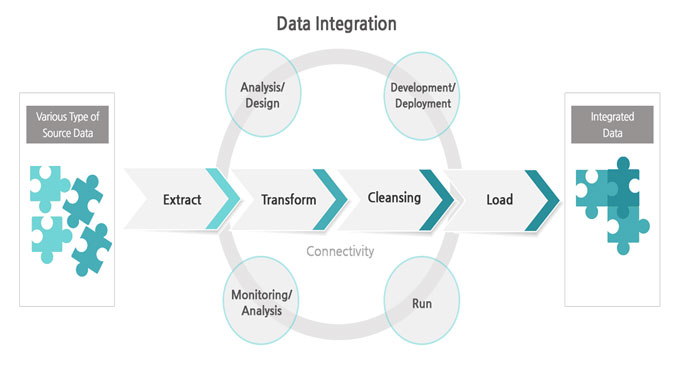
АэЧАСњ ЕЅРЬХЭ ШЎКИИІ РЇЧб ЕЅРЬХЭ ХыЧе Йз СЄСІ
АэЧАСњ ЕЅРЬХЭДТ ДйРНАњ ААРК ЦЏМКРЛ АЎУпОюОп ЧеДЯДй.
ЕЅРЬХЭ ХыЧе Йз СЄСІ РлОїРЧ ИёРћРК РњЧАСњРЧ ПјУЕ ЕЅРЬХЭИІ РЇПЭ ААРК ПфАЧРЛ АЎУс АэЧАСњРЧ ЕЅРЬХЭЗЮ КЏШЏЧЯДТ АЭРдДЯДй.
ЕЅРЬХЭ ХыЧеРК КЙМіРЧ ЕЅРЬХЭ ПјУЕАњ ХыЧе РњРхМвИІ ПЌАсЧЯДТ ЕЅРЬХЭ ЦФРЬЧСЖѓРЮРЛ ХыЧи ЕЅРЬХЭРЧ РЬАќРЛ МіЧрЧеДЯДй. НЧСІЗЮ ПјУЕ ЕЅРЬХЭАЁ БзДыЗЮ РћРчЕЧДТ АцПьДТ ИЙСі ОЪНРДЯДй. ИЙРК АцПь КЙМіРЧ ПјУЕ ЕЅРЬХЭЕщРЛ СЖЧеЧи ЛѕЗЮПю ЕЅРЬХЭ ЧзИёРЛ ИИЕщОю ГЛДТ КЏШЏРлОїРЬ ПфБИЕЫДЯДй.
ЕЅРЬХЭ СЄСІДТ ПјУЕ ЕЅРЬХЭ ШЄРК ХыЧеЕШ ПјУЕ ЕЅРЬХЭРЧ ЦїИЫРЛ ХыРЯЧЯАХГЊ, ДЉЖєАЊРЛ СІАХЧЯАХГЊ, БИКаРк (delimiter) ИІ РдЗТЧЯАХГЊ, ЕЅРЬХЭРЧ КвЧЪПфЧб АЊРЛ СІАХЧЯДТ ЕюРЧ РлОїРЛ ХыЧи АэЧАСњ ЕЅРЬХЭРЧ ПфАЧРЛ АЎУпДТ РлОїРЛ РЧЙЬЧеДЯДй.
1. СЂБйМК (Accessible) : ЕЅРЬХЭ КаМЎАЁЕщРЬ ЧЪПфЧб ЕЅРЬХЭПЁ НБАд СЂБйЧЯАэ УпУтЧв Мі РжОюОп ЧеДЯДй.
2. СЄШЎЕЕ (Accurate) : ЕЅРЬХЭАЁ АЁСіДТ АЊРК НЧСІ ЛѓШВРЛ СЄШЎЧЯАд БтЗЯЧиОп ЧеДЯДй.
3. ПЌАшМК (Coherent) : ЧЯГЊРЧ ЕЅРЬХЭ ЧзИёРК АќЗУЕШ КЙМіРЧ ЕЅРЬХЭ ЧзИёАњ СЄШЎШї СЖЧе (join) ЕЩ Мі РжОюОп ЧеДЯДй.
4. ПЯЗсМК (Complete) : ЕЅРЬХЭДТ ДЉЖєАЊРЛ АЁСЎМДТ ОШЕЫДЯДй.
5. РЯАќМК (Consistent) : ЕПРЯЧб ЕЅРЬХЭ ЧзИёРК СЖСї ГЛ И№Еч АїПЁМ ЕПРЯЧб ЦїИЫРЛ РЏСіЧиОп ЧеДЯДй.
6. ИэЗсМК (Defined) : АЂАЂРЧ ЕЅРЬХЭ ЧзИёРК ИэШЎШї СЄРЧЕЧОю СпРЧРћРЬСі ОЪОЦОп ЧеДЯДй.
7. АќЗУМК (Relevant) : ЕЅРЬХЭДТ ДйПюНКЦЎИВРЧ ЕЅРЬХЭ КаМЎ РлОїАњ АќЗУЕЧОю РжОюОп ЧеДЯДй.
8. ОШСЄМК (Reliable) : СЄШЎЕЕПЭ ПЯЗсМКРЛ АЎУс ЕЅРЬХЭ ЧзИёРЬ СіМгРћРИЗЮ ШЎКИЕЧОюОп ЧеДЯДй.
9. РћНУМК (Timely) : ЕЅРЬХЭДТ РЏШПЧб БтАЃ ГЛПЁ ШЎКИЕЧАэ КаМЎЕЧОюОп ЧеДЯДй.
2. СЄШЎЕЕ (Accurate) : ЕЅРЬХЭАЁ АЁСіДТ АЊРК НЧСІ ЛѓШВРЛ СЄШЎЧЯАд БтЗЯЧиОп ЧеДЯДй.
3. ПЌАшМК (Coherent) : ЧЯГЊРЧ ЕЅРЬХЭ ЧзИёРК АќЗУЕШ КЙМіРЧ ЕЅРЬХЭ ЧзИёАњ СЄШЎШї СЖЧе (join) ЕЩ Мі РжОюОп ЧеДЯДй.
4. ПЯЗсМК (Complete) : ЕЅРЬХЭДТ ДЉЖєАЊРЛ АЁСЎМДТ ОШЕЫДЯДй.
5. РЯАќМК (Consistent) : ЕПРЯЧб ЕЅРЬХЭ ЧзИёРК СЖСї ГЛ И№Еч АїПЁМ ЕПРЯЧб ЦїИЫРЛ РЏСіЧиОп ЧеДЯДй.
6. ИэЗсМК (Defined) : АЂАЂРЧ ЕЅРЬХЭ ЧзИёРК ИэШЎШї СЄРЧЕЧОю СпРЧРћРЬСі ОЪОЦОп ЧеДЯДй.
7. АќЗУМК (Relevant) : ЕЅРЬХЭДТ ДйПюНКЦЎИВРЧ ЕЅРЬХЭ КаМЎ РлОїАњ АќЗУЕЧОю РжОюОп ЧеДЯДй.
8. ОШСЄМК (Reliable) : СЄШЎЕЕПЭ ПЯЗсМКРЛ АЎУс ЕЅРЬХЭ ЧзИёРЬ СіМгРћРИЗЮ ШЎКИЕЧОюОп ЧеДЯДй.
9. РћНУМК (Timely) : ЕЅРЬХЭДТ РЏШПЧб БтАЃ ГЛПЁ ШЎКИЕЧАэ КаМЎЕЧОюОп ЧеДЯДй.
ЕЅРЬХЭ ХыЧе Йз СЄСІ РлОїРЧ ИёРћРК РњЧАСњРЧ ПјУЕ ЕЅРЬХЭИІ РЇПЭ ААРК ПфАЧРЛ АЎУс АэЧАСњРЧ ЕЅРЬХЭЗЮ КЏШЏЧЯДТ АЭРдДЯДй.
ЕЅРЬХЭ ХыЧеРК КЙМіРЧ ЕЅРЬХЭ ПјУЕАњ ХыЧе РњРхМвИІ ПЌАсЧЯДТ ЕЅРЬХЭ ЦФРЬЧСЖѓРЮРЛ ХыЧи ЕЅРЬХЭРЧ РЬАќРЛ МіЧрЧеДЯДй. НЧСІЗЮ ПјУЕ ЕЅРЬХЭАЁ БзДыЗЮ РћРчЕЧДТ АцПьДТ ИЙСі ОЪНРДЯДй. ИЙРК АцПь КЙМіРЧ ПјУЕ ЕЅРЬХЭЕщРЛ СЖЧеЧи ЛѕЗЮПю ЕЅРЬХЭ ЧзИёРЛ ИИЕщОю ГЛДТ КЏШЏРлОїРЬ ПфБИЕЫДЯДй.
ЕЅРЬХЭ СЄСІДТ ПјУЕ ЕЅРЬХЭ ШЄРК ХыЧеЕШ ПјУЕ ЕЅРЬХЭРЧ ЦїИЫРЛ ХыРЯЧЯАХГЊ, ДЉЖєАЊРЛ СІАХЧЯАХГЊ, БИКаРк (delimiter) ИІ РдЗТЧЯАХГЊ, ЕЅРЬХЭРЧ КвЧЪПфЧб АЊРЛ СІАХЧЯДТ ЕюРЧ РлОїРЛ ХыЧи АэЧАСњ ЕЅРЬХЭРЧ ПфАЧРЛ АЎУпДТ РлОїРЛ РЧЙЬЧеДЯДй.
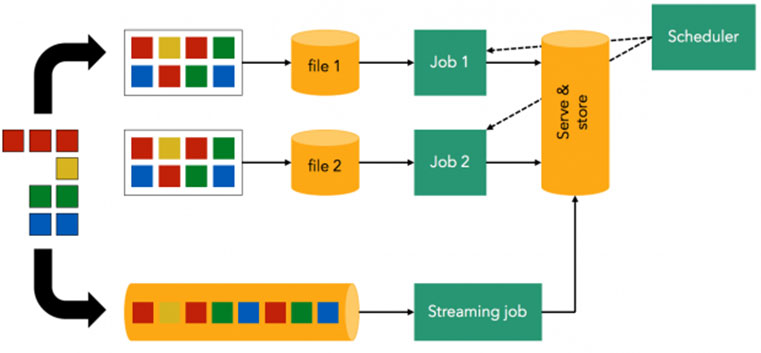
Batch vs Streaming
ЕЅРЬХЭ ХыЧе Йз СЄСІ ДмАшПЁМ АэЗСЧиОп Чв СпПфЧб ПфМв Сп ЧЯГЊДТ ЕЅРЬХЭ РЏРд ЧќХТРдДЯДй. ПжГФЧЯИщ РЬПЁ ЕћЖѓ ЕЅРЬХЭ ХыЧе Йз СЄСІ ЧСЗЮММНКРЧ МКАн РкУМАЁ ДоЖѓСіБт ЖЇЙЎРдДЯДй. РЏРдЧќХТПЁ ЕћЖѓ ЕЅРЬХЭДТ ХЉАд РЏАш (bounded) ЕЅРЬХЭПЭ ЙЋАш (unbounded) ЕЅРЬХЭЗЮ БИКаЕЫДЯДй.
РЏАш (bounded) ЕЅРЬХЭДТ РЏРдЕЧДТ ЕЅРЬХЭПЁ ИэШЎЧб НУАЃ АцАшАЁ СИРчЧЯДТ ЕЅРЬХЭИІ ИЛЧеДЯДй. ПЙИІ ЕщОю, ИХРЯ СЄЧиСј НУАЃПЁ ОюСІ МіС§Чб ЕЅРЬХЭИІ ХыЧе РњРхМвПЁ РЯА§ РћРчЧЯДТ РлОїРЛ МіЧрЧбДйИщ РћРч ДыЛѓРЬ ЕЧДТ ЕЅРЬХЭДТ АњАХ 24НУАЃ ЕПОШ МіС§ЕШ ЕЅРЬХЭРЬИч 24НУАЃРЬЖѓДТ НУАЃ АцАшАЁ СИРчЧеДЯДй. ЕћЖѓМ РЬ АцПь РћРчЧЯДТ ЕЅРЬХЭДТ РЏАш ЕЅРЬХЭРдДЯДй. РЏАш ЕЅРЬХЭДТ КЛСњРћРИЗЮ АњАХ РЯСЄ БтАЃРЧ ЕЅРЬХЭИІ УрРћЧб АсАњЙАРЬИч РЬЗЏЧб ЕЅРЬХЭДТ РЇ ПЙНУУГЗГ СжБтРћРИЗЮ РЯА§УГИЎЧЯДТ АЭРЬ РћЧеЧеДЯДй. РЬЗЏЧб РЯА§УГИЎИІ ЙшФЁ УГИЎ (Batch processing) ЖѓАэ ЧЯИч АЁРх КИЦэРћРЬАэ АЫСѕЕШ ЙшФЁ УГИЎ БтМњРЬ ETL (Extract, Transform, Load) РдДЯДй.
ЙшФЁ УГИЎРЧ РхСЁ
ЙшФЁ УГИЎРЧ ДмСЁ
АќЗУ СІЧА : Informatica PowerCenter, IBM Data Stage
ЙЋАш (unbounded) ЕЅРЬХЭДТ РЏАш ЕЅРЬХЭПЭДТ ЙнДыЗЮ ИэШЎЧб НУАЃ АцАшАЁ ОјДТ ЕЅРЬХЭРдДЯДй. ВїРгОјРЬ ШхИЃДТ НУГСЙАУГЗГ ПјУЕРИЗЮКЮХЭ АшМгЧиМ ШъЗЏ ЕщОюПРДТ ЕЅРЬХЭИІ УрРћЧЯСі ОЪАэ РЏРдЕЧДТ НУСЁПЁ ЙйЗЮЙйЗЮ УГИЎЧЯДТ ЙцНФРЬ РћЧеЧеДЯДй. РЬЗЏЧб УГИЎ ЙцНФРЛ НКЦЎИЎЙж УГИЎ (Streaming processing) РЬЖѓАэ ЧЯИч, НЧНУАЃ ШЄРК СиНЧНУАЃ ЕЅРЬХЭ КаМЎРЛ РЇЧиМДТ ЧЪМіРћРЮ АњСЄРдДЯДй. ПјУЕПЁМ ЕЅРЬХЭАЁ Л§МКЕЧДТ НУСЁРК РгРЧРћРЬЙЧЗЮ ЛчНЧ И№Еч ЕЅРЬХЭДТ КЛСњРћРИЗЮ ЙЋАш ЕЅРЬХЭРдДЯДй. ЙЋАш ЕЅРЬХЭИІ РЯСЄ БтАЃ УрРћЧиМ РЏАш ЕЅРЬХЭШ ЧЯПЉ ЙшФЁ УГИЎЧв АЭРЮСі, ОЦДЯИщ ЙЋАш ЕЅРЬХЭРЮ ЛѓХТЗЮ БзДыЗЮ НКЦЎИЎЙж УГИЎЧв АЭРЮСіДТ ЕЅРЬХЭ КаМЎ ПфАЧПЁ ЕћЖѓ АсСЄЕЫДЯДй. ДыЧЅРћРЮ НКЦЎИЎЙж УГИЎ БтМњРК ЙшФЁ РлОї СжБтИІ ТЊАд МГСЄЧЯДТ ИЖРЬХЉЗЮ ЙшФЁ (Micro batch), КЙМіРЧ ПјУЕПЁМ РгРЧ НУСЁПЁ ЙпЛ§ЧЯДТ РЬКЅЦЎПЁ РЧЧи Л§МКЕЧДТ ЕЅРЬХЭЕщРЛ РЏРЧЙЬЧб ДмРЇЗЮ СЖЧе Йз КаЗљЧЯДТ CEP (Complex Event Processing) РдДЯДй.
НКЦЎИЎЙж УГИЎРЧ РхСЁ
НКЦЎИЎЙж УГИЎРЧ ДмСЁ
АќЗУ СІЧА : Informatica CEP
РЏАш (bounded) ЕЅРЬХЭДТ РЏРдЕЧДТ ЕЅРЬХЭПЁ ИэШЎЧб НУАЃ АцАшАЁ СИРчЧЯДТ ЕЅРЬХЭИІ ИЛЧеДЯДй. ПЙИІ ЕщОю, ИХРЯ СЄЧиСј НУАЃПЁ ОюСІ МіС§Чб ЕЅРЬХЭИІ ХыЧе РњРхМвПЁ РЯА§ РћРчЧЯДТ РлОїРЛ МіЧрЧбДйИщ РћРч ДыЛѓРЬ ЕЧДТ ЕЅРЬХЭДТ АњАХ 24НУАЃ ЕПОШ МіС§ЕШ ЕЅРЬХЭРЬИч 24НУАЃРЬЖѓДТ НУАЃ АцАшАЁ СИРчЧеДЯДй. ЕћЖѓМ РЬ АцПь РћРчЧЯДТ ЕЅРЬХЭДТ РЏАш ЕЅРЬХЭРдДЯДй. РЏАш ЕЅРЬХЭДТ КЛСњРћРИЗЮ АњАХ РЯСЄ БтАЃРЧ ЕЅРЬХЭИІ УрРћЧб АсАњЙАРЬИч РЬЗЏЧб ЕЅРЬХЭДТ РЇ ПЙНУУГЗГ СжБтРћРИЗЮ РЯА§УГИЎЧЯДТ АЭРЬ РћЧеЧеДЯДй. РЬЗЏЧб РЯА§УГИЎИІ ЙшФЁ УГИЎ (Batch processing) ЖѓАэ ЧЯИч АЁРх КИЦэРћРЬАэ АЫСѕЕШ ЙшФЁ УГИЎ БтМњРЬ ETL (Extract, Transform, Load) РдДЯДй.
ЙшФЁ УГИЎРЧ РхСЁ
1. АцАш ГЛПЁ УрРћЕШ ЕЅРЬХЭПЁ ДыЧб ПЯАсМКАњ ХыРЯМК СІАј
2. ЛчРќ СЄРЧЕШ УГИЎИІ СжБтРћРИЗЮ МіЧрЧЯЙЧЗЮ ЛѓДыРћРИЗЮ БИЧіРЬ НБАэ ОШСЄРћРг
2. ЛчРќ СЄРЧЕШ УГИЎИІ СжБтРћРИЗЮ МіЧрЧЯЙЧЗЮ ЛѓДыРћРИЗЮ БИЧіРЬ НБАэ ОШСЄРћРг
ЙшФЁ УГИЎРЧ ДмСЁ
1. АцАш БтАЃ ЕПОШ ЕЅРЬХЭИІ РћРчЧЯПЉ КаМЎЧв Мі ОјОю РћНУМК РњЧЯ
2. СЄЧиСј НУАЃ ЕПОШ ИЎМвНКИІ РЯА§ ЕЅРЬХЭ УГИЎПЁ С§СпЧЯЙЧЗЮ СЄБтРћ ДйПюХИРг ЙпЛ§
2. СЄЧиСј НУАЃ ЕПОШ ИЎМвНКИІ РЯА§ ЕЅРЬХЭ УГИЎПЁ С§СпЧЯЙЧЗЮ СЄБтРћ ДйПюХИРг ЙпЛ§
АќЗУ СІЧА : Informatica PowerCenter, IBM Data Stage
ЙЋАш (unbounded) ЕЅРЬХЭДТ РЏАш ЕЅРЬХЭПЭДТ ЙнДыЗЮ ИэШЎЧб НУАЃ АцАшАЁ ОјДТ ЕЅРЬХЭРдДЯДй. ВїРгОјРЬ ШхИЃДТ НУГСЙАУГЗГ ПјУЕРИЗЮКЮХЭ АшМгЧиМ ШъЗЏ ЕщОюПРДТ ЕЅРЬХЭИІ УрРћЧЯСі ОЪАэ РЏРдЕЧДТ НУСЁПЁ ЙйЗЮЙйЗЮ УГИЎЧЯДТ ЙцНФРЬ РћЧеЧеДЯДй. РЬЗЏЧб УГИЎ ЙцНФРЛ НКЦЎИЎЙж УГИЎ (Streaming processing) РЬЖѓАэ ЧЯИч, НЧНУАЃ ШЄРК СиНЧНУАЃ ЕЅРЬХЭ КаМЎРЛ РЇЧиМДТ ЧЪМіРћРЮ АњСЄРдДЯДй. ПјУЕПЁМ ЕЅРЬХЭАЁ Л§МКЕЧДТ НУСЁРК РгРЧРћРЬЙЧЗЮ ЛчНЧ И№Еч ЕЅРЬХЭДТ КЛСњРћРИЗЮ ЙЋАш ЕЅРЬХЭРдДЯДй. ЙЋАш ЕЅРЬХЭИІ РЯСЄ БтАЃ УрРћЧиМ РЏАш ЕЅРЬХЭШ ЧЯПЉ ЙшФЁ УГИЎЧв АЭРЮСі, ОЦДЯИщ ЙЋАш ЕЅРЬХЭРЮ ЛѓХТЗЮ БзДыЗЮ НКЦЎИЎЙж УГИЎЧв АЭРЮСіДТ ЕЅРЬХЭ КаМЎ ПфАЧПЁ ЕћЖѓ АсСЄЕЫДЯДй. ДыЧЅРћРЮ НКЦЎИЎЙж УГИЎ БтМњРК ЙшФЁ РлОї СжБтИІ ТЊАд МГСЄЧЯДТ ИЖРЬХЉЗЮ ЙшФЁ (Micro batch), КЙМіРЧ ПјУЕПЁМ РгРЧ НУСЁПЁ ЙпЛ§ЧЯДТ РЬКЅЦЎПЁ РЧЧи Л§МКЕЧДТ ЕЅРЬХЭЕщРЛ РЏРЧЙЬЧб ДмРЇЗЮ СЖЧе Йз КаЗљЧЯДТ CEP (Complex Event Processing) РдДЯДй.
НКЦЎИЎЙж УГИЎРЧ РхСЁ
1. ЕЅРЬХЭ РЏРд НУСЁКЮХЭ УжСО КаМЎ НУСЁБюСіРЧ СіПЌ (latency) УжМвШ
2. СІДыЗЮ МГАшЕШ НКЦЎИЎЙж УГИЎДТ ЙшФЁ УГИЎИІ КвЧЪПфЧЯАд ИИЕщ Мі РжРН
2. СІДыЗЮ МГАшЕШ НКЦЎИЎЙж УГИЎДТ ЙшФЁ УГИЎИІ КвЧЪПфЧЯАд ИИЕщ Мі РжРН
НКЦЎИЎЙж УГИЎРЧ ДмСЁ
1. БтСИ СЄКИАшПЁМДТ АХРЧ ЛчПыЕЧСі ОЪОЦ АќЗУ БтМњПЊЗЎРЬ СІЧбЕЧОю РжРН
2. ЙшФЁ УГИЎПЁ КёЧи ШЮОР ДйОчЧб ПфМвИІ АэЗСЧиОп ЧЯДТ КЙРтЧб РлОї
2. ЙшФЁ УГИЎПЁ КёЧи ШЮОР ДйОчЧб ПфМвИІ АэЗСЧиОп ЧЯДТ КЙРтЧб РлОї
АќЗУ СІЧА : Informatica CEP
Top-down vs Bottom-up
СЄСІЕЧСі ОЪРК ПјУЕ ЕЅРЬХЭИІ 1ТїРћРИЗЮ СЄСІЧбДй ЧЯДѕЖѓЕЕ И№Еч ЙЎСІАЁ ЧиАсЕЧДТ АЭРК ОЦДеДЯДй. АХРЧ И№Еч СЖСїПЁДТ КЙМіРЧ ОюЧУИЎФЩРЬМЧЕщРЬ СИРчЧЯАэ АЂ ОюЧУИЎФЩРЬМЧИЖДй КАЕЕРЧ ЕЅРЬХЭКЃРЬНКИІ АЁСіАэ РжНРДЯДй. РЬ АцПь ЙпЛ§Чв Мі РжДТ ЙЎСІДТ ХЉАд ЕЮ АЁСіРдДЯДй.
РЬЗЏЧб ЙЎСІПЁ ДыУГЧЯБт РЇЧб ЙцОШРК ХЉАд ЕЮ АЁСіАЁ РжНРДЯДй.
1. ЕПРЯЧб ДыЛѓПЁ ДыЧб СпКЙЕШ ЛѓРЬЧб ЕЅРЬХЭ
2. ЕЅРЬХЭ КаЗљ Йз УМАшШ КЮРч
КаЛъЕШ ЕЅРЬХЭКЃРЬНКЕщРК АЂАЂРЧ ЧЪПфПЭ Р§ТїПЁ ЕћЖѓ ЕЅРЬХЭИІ РдЗТ, УГИЎ, РњРхЧЯЙЧЗЮ ЕПРЯЧб ДыЛѓ (Entity) ПЁ ДыЧб ЕЅРЬХЭЖѓЕЕ Бз ГЛПыРЬ МЗЮ ЛѓРЬЧб АцПьАЁ РЯЙнРћРдДЯДй. ПЙИІ ЕщОю, АГРЮ АэАДПЁ ДыЧб ЕЅРЬХЭИІ ПЕОїАќИЎ НУНКХлПЁМДТ СжЙЎ Йз ИХУт БтСиРИЗЮ АќИЎЧЯАэ, ИЖФЩЦУ НУНКХлПЁМДТ ЧСЗЮИ№МЧ ДыЛѓРк БтСиРИЗЮ АќИЎЧЯАд ЕЧИщ ЖШААРК АэАДПЁ ДыЧб ЕЅРЬХЭАЁ ЕЮ ЕЅРЬХЭКЃРЬНКПЁ МЗЮ ДйИЅ ГЛПыРИЗЮ РњРхЕЧАд ЕЫДЯДй. РЬЗБ ЛѓШВПЁМДТ Чб СЖСїРЬ РќУМ АэАДРЧ МіИІ ЦФОЧЧЯДТ АЭЕЕ ШћЕщАд ЕЫДЯДй.
2. ЕЅРЬХЭ КаЗљ Йз УМАшШ КЮРч
КаЛъЕШ ЕЅРЬХЭКЃРЬНКПЁ РњРхЕШ МіИЙРК ЕЅРЬХЭЕщ Сп ОюЖВ ЕЅРЬХЭАЁ ОюЖВ СжСІ ШЄРК ДыЛѓПЁ АќЧб АЭРЮСі ЦФОЧЧЯАэ КаЗљЧЯДТ АЭРК ИХПь ОюЗСПю РЯРдДЯДй. МіИЙРК ПјУЕПЁМ ДйОчЧб ЕЅРЬХЭЕщРЬ Л§МКЕЧИщ СЖСї ГЛПЁ ОюЖВ ЕЅРЬХЭАЁ ОюЕ№ПЁ РжДТСі ОЫБтАЁ ИХПь ОюЗЦНРДЯДй. ЕЅРЬХЭИІ СЖСїРЧ РкЛъРЬЖѓАэ Л§АЂЧбДйИщ РжОюМДТ ОШЕЩ РЯРдДЯДй.
РЬЗЏЧб ЙЎСІПЁ ДыУГЧЯБт РЇЧб ЙцОШРК ХЉАд ЕЮ АЁСіАЁ РжНРДЯДй.
1. Top-down СЂБйЙцНФ
2. Bottom-up СЂБйЙцНФ
Top-downАњ Bottom-upРК МЗЮ ДыИГЕЧДТ АЭРЬ ОЦДб ЛѓШЃ КИПЯРћРЮ СЂБйЙцНФРдДЯДй. Top-down РИЗЮ СЖСїРЧ БйАЃРЬ ЕЧДТ ЛѓРЇ ЕЅРЬХЭ УМАшИІ СЄРЧЧЯАэ, Bottom-up ЙцНФРИЗЮ ЧЯКЮ УМАшПЁ РЏПЌМКРЛ КИРхЧЯДТ АЭРЬ АЁРх ЙйЖїСїЧб ЕЅРЬХЭ ХыЧе Йз КаЗљ ЙцНФРЬЖѓАэ Чв Мі РжНРДЯДй.
НБАд Л§АЂЧв Мі РжДТ ЙцОШРК СЖСї ГЛ РќУМ ЕЅРЬХЭ УМАшИІ СЄРЧЧЯПЉ СЖСї ГЛ И№Еч ЕЅРЬХЭИІ РЬ УМАшПЁ ИТЕЕЗЯ БИМКЧЯДТ ЙцОШРдДЯДй. АЂ КЮМРЧ ОїЙЋ РќЙЎАЁ, ЕЅРЬХЭ РќЙЎАЁ ЕюРЬ РЯСЄ БтАЃ ЕПОШ ГэРЧИІ АХУФ КаЗљ УМАшИІ СЄРЧЧЯАэ, МЗЮ ДйИЅ ЙіРќРЛ ЧуПыЧиМДТ ОШЕЩ ЧйНЩ ЕЅРЬХЭРЧ НКХАИЖИІ СЄРЧЧеДЯДй. КИХы MDM (Master Data Management), Metadata ЕюРЬ РЬЗЏЧб СЂБйЙцНФРЛ УыЧеДЯДй. РЬ ЙцНФРК ХЋ БзИВПЁМРЧ УМАшИІ РтРЛ Мі РжДйДТ РхСЁРК РжСіИИ, КЏШЙЋНжЧб ЕЅРЬХЭРЧ ЧіНЧРЛ ЙоОЦЕщРЬБтПЁДТ РЏПЌЧЯСі ИјЧЯДйДТ ЙЎСІСЁРЬ РжНРДЯДй.
АќЗУ СІЧА : Informatica MDM, Informatica MetaData
АќЗУ СІЧА : Informatica MDM, Informatica MetaData
2. Bottom-up СЂБйЙцНФ
РЬИІ КИПЯЧЯБт РЇЧи УжБй ЕюРхЧб ЙцНФРК КаЛъЕШ ЕЅРЬХЭРЧ ХыЧеРЛ ИгНХЗЏДзРЛ ШАПыЧи РкЕПШЧЯДТ ЕЅРЬХЭ ХЅЗЙРЬМЧ (Data Curation) РдДЯДй. МіИЙРК ЕЅРЬХЭИІ ЛчЖїРЬ РЯРЯРЬ ЛьЧЧАэ РЬИІ ХыЧеЧЯАэ КаЗљЧЯДТ АЭРК ЛчНЧЛѓ КвАЁДЩЧеДЯДй. ЧЯСіИИ, ИгНХЗЏДзРЛ ШАПыЧЯПЉ РЏЛчЧб ЗЙФкЕхЕщРЧ ХыЧеАњ КаЗљИІ РЯСЄ МіСи РкЕПШЧбДйИщ ПРШїЗС КЏШЧЯДТ ОїЙЋШЏАцПЁ ЕћИЅ ЕЅРЬХЭРЧ КЏШПЁ РЏПЌЧЯАд ДыУГЧв Мі РжНРДЯДй. TamrПЭ ААРК ЛѕЗЮПю ХјРЬ ЙйЗЮ РЬЗЏЧб ПЊЧвРЛ МіЧрЧв Мі РжНРДЯДй.
АќЗУ СІЧА : Tamr
АќЗУ СІЧА : Tamr
Top-downАњ Bottom-upРК МЗЮ ДыИГЕЧДТ АЭРЬ ОЦДб ЛѓШЃ КИПЯРћРЮ СЂБйЙцНФРдДЯДй. Top-down РИЗЮ СЖСїРЧ БйАЃРЬ ЕЧДТ ЛѓРЇ ЕЅРЬХЭ УМАшИІ СЄРЧЧЯАэ, Bottom-up ЙцНФРИЗЮ ЧЯКЮ УМАшПЁ РЏПЌМКРЛ КИРхЧЯДТ АЭРЬ АЁРх ЙйЖїСїЧб ЕЅРЬХЭ ХыЧе Йз КаЗљ ЙцНФРЬЖѓАэ Чв Мі РжНРДЯДй.
SOFTLINE
ADDRESS
СжНФШИЛч МвЧСЦЎЖѓРЮ
АцБтЕЕ АэОчНУ ДіОчБИ ПыЧіЗЮ 3, 2~3F
CONTACT US
РЬИоРЯ : jhlee@softline.biz
РќШЙјШЃ : 070-7770-4174
HOT-LINE : softlnie@softline.biz