경직된 데이터 유통의 위험성
데이터 시스템에서 데이터는 원천에서부터 최종 데이터 소비자까지 흘러갑니다. 원천이 많지않고 소비자의 요건이 비교적 일관되고 단순하다면 이 유통과정을 구현하거나 관리하는 데에 많은 비용이 소비되지 않겠지만 현실은 그렇지 않습니다. 조직 내 거의 모든 어플리케이션들은 DBMS를 가지고 있고, 업무 산출물은 그룹웨어 혹은 부서 별 파일서버에 파일 형태로 저장되어 있으며, 수많은 장비들은 매분 매초 엄청난 양의 로그 데이터를 생성합니다. 소셜 미디어 등 조직 외부의 데이터를 활용하는 경우도 있으며, 고객 행동 패턴 분석을 위한 실시간 트래킹 데이터를 수집하기도 합니다.
조직 내 수많은 데이터 소비자들 역시 각자의 목적에 따라 어떤 데이터를, 어떤 형태로, 어떻게 가공하여, 어느 정도의 데이터 지연 (latency) 까지 감수할 것인지 등에 대한 요건을 가지고 있습니다. 수많은 원천으로부터 수집된 데이터는 이러한 요건에 맞추어 정제된 후 다양한 시스템에 저장됩니다
조직 내 수많은 데이터 소비자들 역시 각자의 목적에 따라 어떤 데이터를, 어떤 형태로, 어떻게 가공하여, 어느 정도의 데이터 지연 (latency) 까지 감수할 것인지 등에 대한 요건을 가지고 있습니다. 수많은 원천으로부터 수집된 데이터는 이러한 요건에 맞추어 정제된 후 다양한 시스템에 저장됩니다
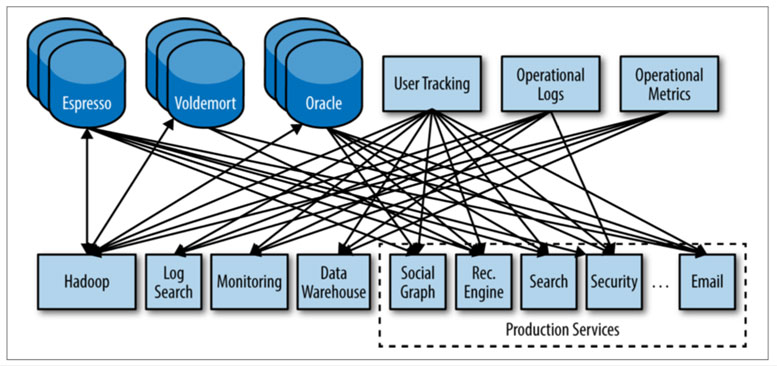
데이터 허브의 등장
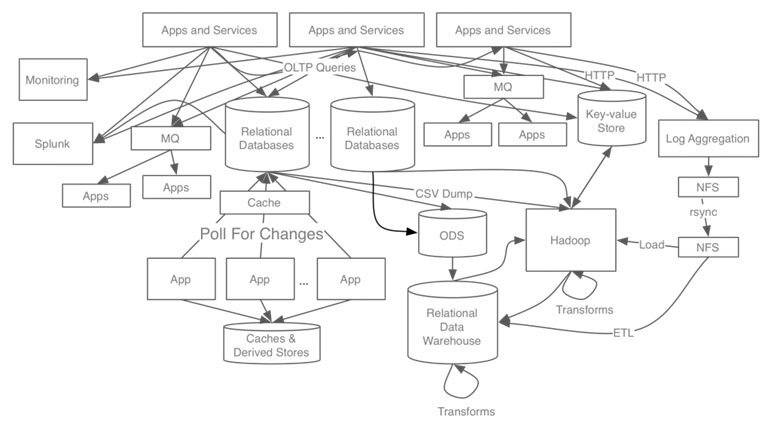
이처럼 복잡하게 얽힌 데이터 파이프라인을 구현하고 관리하는 작업을 통틀어 데이터 배관작업 (Data plumbing) 이라고 합니다. 데이터 배관작업은 데이터 엔지니어들이 가장 많은 시간을 투자해야 하는 작업이며, 그러다 보니 엔지니어 인력에 대한 의존도도 높습니다. 이러한 노력에도 불구하고 N-to-N 유통이라는 근본적인 구조적 문제를 해결하지 않는 이상 유통망의 유연성을 확보하기는 여전히 매우 어렵습니다.
N-to-N 구성에서는 데이터 생산자와 소비자가 직접 연결되어 있으므로 데이터 엔지니어는 데이터를 주고받는 시점 및 이관 대상 데이터를 양측에 모두 설정해 주어야 합니다. 이러한 설정작업이 생산자와 소비자가 늘어날 때마다 기하급수적으로 늘어난다는 것이 N-to-N 구성의 최대 단점입니다 (최다 N*N개의 파이프라인). 생산자 그룹과 소비자 그룹이 서로 다른 이기종 시스템들로 혼합되어 있다면 엔지니어의 기술관점에서 복잡도가 크게 증가합니다.
데이터 허브 기반의 N-to-1-to-N 구성에서는 생산자와 소비자의 수가 아무리 많아지더라도 데이터 엔지니어는 생산자-허브, 허브-소비자와의 연결설정을 별도로 수행하여 (최다 N+N개의 파이프라인) 관리해야 할 파이프라인의 수를 크게 줄일 수 있습니다. 또한, 기술적으로도 엔지니어는 이기종 시스템 간 연계가 아니라 허브와의 연계 설정만 수행하므로 복잡도가 크게 낮아집니다. 또 다른 장점으로는 데이터 허브에서 연결된 모든 데이터 파이프라인에 대한 통합 모니터링 및 관리가 가능하다는 점입니다
관련 제품 : Informatica Data Integration Hub
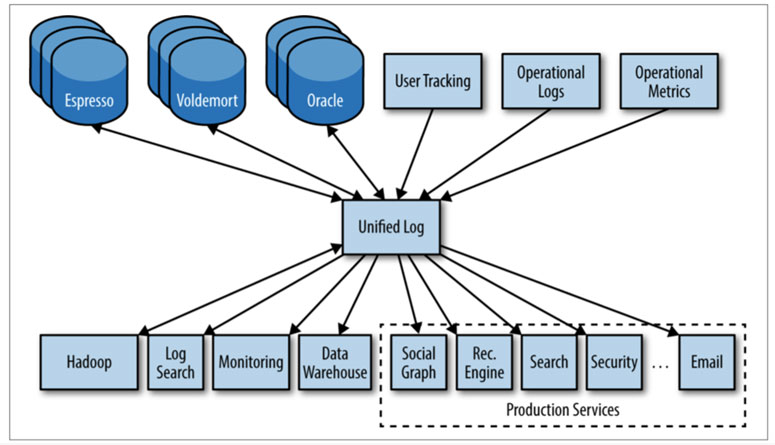
N-to-N 구성에서는 데이터 생산자와 소비자가 직접 연결되어 있으므로 데이터 엔지니어는 데이터를 주고받는 시점 및 이관 대상 데이터를 양측에 모두 설정해 주어야 합니다. 이러한 설정작업이 생산자와 소비자가 늘어날 때마다 기하급수적으로 늘어난다는 것이 N-to-N 구성의 최대 단점입니다 (최다 N*N개의 파이프라인). 생산자 그룹과 소비자 그룹이 서로 다른 이기종 시스템들로 혼합되어 있다면 엔지니어의 기술관점에서 복잡도가 크게 증가합니다.
데이터 허브 기반의 N-to-1-to-N 구성에서는 생산자와 소비자의 수가 아무리 많아지더라도 데이터 엔지니어는 생산자-허브, 허브-소비자와의 연결설정을 별도로 수행하여 (최다 N+N개의 파이프라인) 관리해야 할 파이프라인의 수를 크게 줄일 수 있습니다. 또한, 기술적으로도 엔지니어는 이기종 시스템 간 연계가 아니라 허브와의 연계 설정만 수행하므로 복잡도가 크게 낮아집니다. 또 다른 장점으로는 데이터 허브에서 연결된 모든 데이터 파이프라인에 대한 통합 모니터링 및 관리가 가능하다는 점입니다
관련 제품 : Informatica Data Integration Hub
유통과정에서의 변환
데이터는 항상 목적에 맞도록 변형됩니다. 데이터 소비자마다 다른 목적을 가지고 데이터를 변환하기에 MVOT (Multiple Versions of Truth) 가 존재합니다. 해당 부서에서만 참조하는 데이터 혹은 중요도가 높지 않아 참조되지 않는 데이터라면 유통과정에서의 변환에 의해 버전마다 데이터가 상이한 경우가 큰 문제가 되지 않을 수 있지만 고객 정보, 매출 정보, 원가 정보 등 핵심적인 데이터의 경우 심각한 문제로 번질 수 있습니다. 따라서 이러한 핵심 데이터들은 MVOT로 인해 잘못된 값이 유통되지 않도록 핵심 데이터에 대해서는 SSOT (Single Source of Truth) 를 한 곳에 저장해 나머지 소비자들은 이 데이터를 참조만 하고 변환은 하지 못하도록 할 필요가 있습니다. 이것이 MDM (Master Data Management) 입니다.
관련 제품 : Informatica MDM
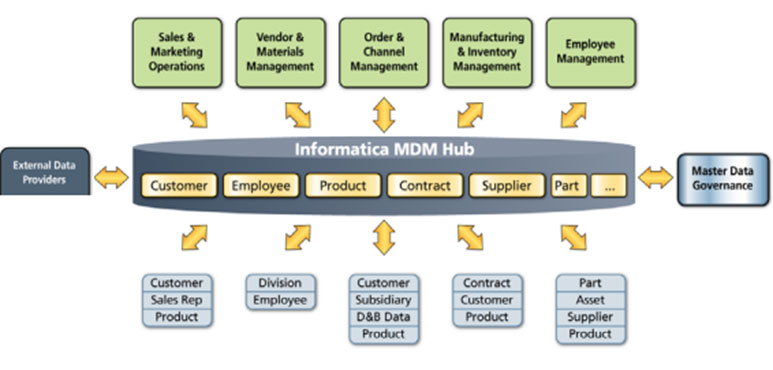
관련 제품 : Informatica MDM
개인정보 보호와 데이터 보안
빅데이터 시대에 접어들 무렵부터 지금까지 개인정보 보호에 대한 이슈는 계속해서 커져 왔습니다. 특히 머신러닝 기반의 AI는 데이터를 원료로 동작하는만큼 조직들이 필요로 하는 데이터는 과거와 비교할 수 없을 정도로 많아졌습니다. 그러다보니 이제 개인을 특정할 수 있는 수준의 데이터들이 남용될 가능성이 높아진 것이 빅데이터 시대의 그림자입니다.
그리고 최근 가장 널리 알려진 개인정보 보호 규제가 바로 GDPR (General Data Protection Regulation) 입니다. GDPR은 특히나 개인정보에 민감한 EU에서 만들어진 개인정보 보호에 대한 제반 원칙과 규칙을 정의한 법규로서 현재 EU 국가들과 거래하는 모든 기업들은 반드시 준수해야만 합니다. 더 나아가 GDPR은 전 세계적으로 개인정보 보호의 귀감이 되어 많은 조직들이 EU와의 비즈니스 여부와 상관없이 GDPR 준수라는 것이 조직의 이미지 개선에 도움을 주는 상황이 되었습니다. GDPR은 비단 개인정보 보호만이 아니라 데이터 유출, 데이터 접근 등 포괄적인 내용을 포함하고 있어 여러 조직 및 국가들이 데이터 보안의 근간으로 삼고 있는 추세입니다.
이런 상황 속에서 조직들은 데이터 보안을 지키지 않았을 경우 받게 될 불이익을 최소화하고자 DPO (Data Protection Officer) 와 같은 새로운 고위직을 만들고, 조직 내 법무 부서는 데이터 오용을 방지하고 그로 인한 피해를 최소화하기 위한 대응팀을 만들기도 합니다. 이제 데이터 엔지니어들에게 있어 데이터 보안은 과거처럼 번거로운 부가업무가 아닌 반드시 해야 할 업무의 범위에 들어왔습니다.
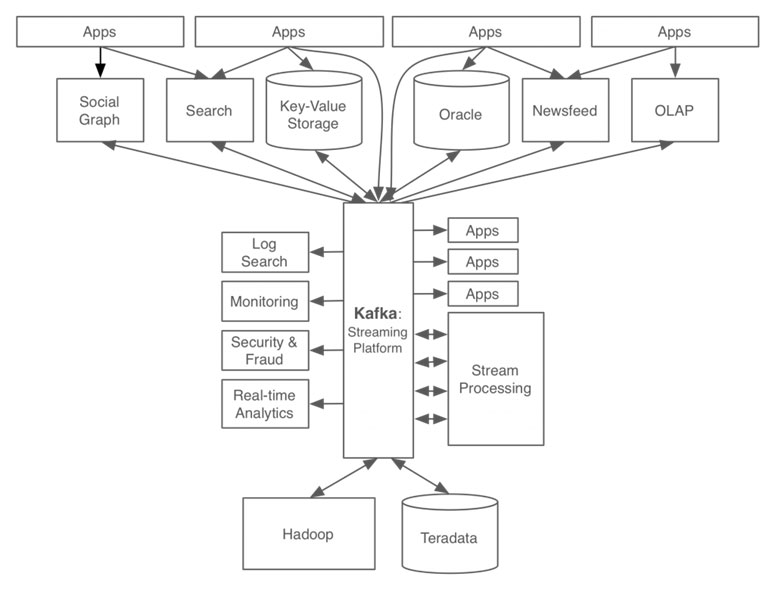
그리고 최근 가장 널리 알려진 개인정보 보호 규제가 바로 GDPR (General Data Protection Regulation) 입니다. GDPR은 특히나 개인정보에 민감한 EU에서 만들어진 개인정보 보호에 대한 제반 원칙과 규칙을 정의한 법규로서 현재 EU 국가들과 거래하는 모든 기업들은 반드시 준수해야만 합니다. 더 나아가 GDPR은 전 세계적으로 개인정보 보호의 귀감이 되어 많은 조직들이 EU와의 비즈니스 여부와 상관없이 GDPR 준수라는 것이 조직의 이미지 개선에 도움을 주는 상황이 되었습니다. GDPR은 비단 개인정보 보호만이 아니라 데이터 유출, 데이터 접근 등 포괄적인 내용을 포함하고 있어 여러 조직 및 국가들이 데이터 보안의 근간으로 삼고 있는 추세입니다.
이런 상황 속에서 조직들은 데이터 보안을 지키지 않았을 경우 받게 될 불이익을 최소화하고자 DPO (Data Protection Officer) 와 같은 새로운 고위직을 만들고, 조직 내 법무 부서는 데이터 오용을 방지하고 그로 인한 피해를 최소화하기 위한 대응팀을 만들기도 합니다. 이제 데이터 엔지니어들에게 있어 데이터 보안은 과거처럼 번거로운 부가업무가 아닌 반드시 해야 할 업무의 범위에 들어왔습니다.
