ЕЅРЬХЭ НКХфИЎСі КЏУЕЛч (from SMP to MPP)
ЕЅРЬХЭИІ ОШСЄРћРЬАэ КёПы ШПРВРћРИЗЮ РњРхЧЯАэРк ЧЯДТ ПфАЧРК ФФЧЛХЭРЧ ХКЛ§ НУСЁКЮХЭ СИРчЧи ПдНРДЯДй. 1990ГтДы ШФЙнБюСі РЬЗЏЧб ПфАЧРЛ ИИСЗНУХАДТ РхБтРћРЮ ЕЅРЬХЭ РњРхМвДТ ДыПыЗЎРЧ АэМКДЩ АэКёПы НКХфИЎСіПДНРДЯДй. РЬЗЏЧб СЂБй ЙцНФРК СЄКИШ МіСиРЬ ГєОЦСіАэ КђЕЅРЬХЭ НУДыПЁ АЁБюПіСіИщМ ЕЅРЬХЭРЧ ОчРЬ ЦјЙпРћРИЗЮ СѕАЁЧЯАэ ЕЅРЬХЭПЁ ДыЧб МіПфАЁ ДУОюГЊРк СЁТї НЩАЂЧб ЙЎСІИІ ЕхЗЏГЛБт НУРлЧеДЯДй
АЁРх ХЋ ЙЎСІДТ КёПыРдДЯДй. РњРхЧиОп Чв ЕЅРЬХЭРЧ ОчРЬ ЦјЙпРћРИЗЮ ДУОюГ ЕЅДй ОюЧУИЎФЩРЬМЧРЧ МіПЭ СОЗљЕЕ ДУОюГЊ НКХфИЎСіРЧ СѕМГАњ НХБдЕЕРд КёПыРЬ IT ПЙЛъПЁМ ГЪЙЋГЊ ХЋ КёСпРЛ ТїСіЧЯАд ЕЧОњНРДЯДй. НКХфИЎСі АЁЛѓШИІ ХыЧб ОР ЧСЗЮКёСЎДз (Thin provisioning) РЛ РћПыЧи НКХфИЎСі АЁПыЗќРЛ ГєРЬДТ ЕЅПЁЕЕ ЧбАшАЁ ЙпЛ§Чв МіЙлПЁ ОјОњНРДЯДй.
ЕЮЙјТА ЙЎСІДТ МКДЩРдДЯДй. ЦЏШї ДыПыЗЎ ЕЅРЬХЭ УГИЎПЁ ПфБИЕЧДТ ГєРК ОВЗчЧВРЛ СІАјЧЯСі ИјЧпНРДЯДй. ИЙРК КёПыРЛ ЕщПЉ НКХфИЎСіПЁМКЮХЭ МЙіБюСіРЧ ЕЅРЬХЭ РќМлМгЕЕИІ ЧтЛѓНУХААэРк SAN, Infiniband Ею ДйОчЧб АэМг НКХфИЎСі ГзЦЎПіХЉИІ РћПыЧЯАэ НКХфИЎСі РкУМ I/O МКДЩРЛ ГєРЬДѕЖѓЕЕ, АсБЙ ДыПыЗЎ ЕЅРЬХЭАЁ Чб АїПЁ ИєЗС НКХфИЎСі ПЕПЊРЬ КДИёРЬ ЕЧДТ БйКЛРћРЮ ЙЎСІСЁРЛ ОШАэ РжОњНРДЯДй.
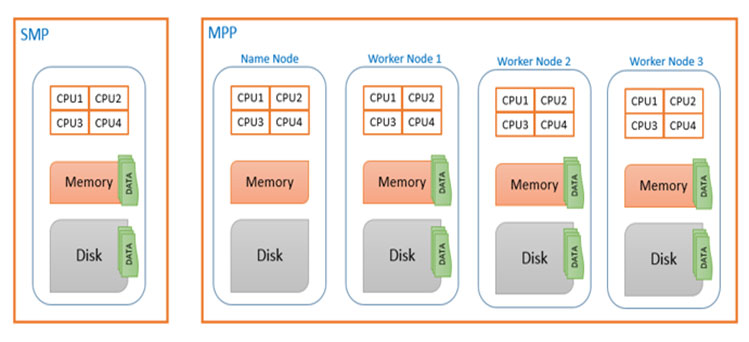
РЬУГЗГ КЙМіРЧ ОюЧУИЎФЩРЬМЧ МЙіЕщРЬ ХыЧе НКХфИЎСі ЗЙРЬОюПЁ ЕЅРЬХЭИІ РњРхЧЯДТ БИСЖИІ SMP (Symmetric Multi-Processing) РЬЖѓАэ ЧеДЯДй. SMP БИСЖПЁМДТ ЕЅРЬХЭ ПыЗЎРЬГЊ МКДЩ ЧтЛѓРЛ РЇЧиМДТ РхКё РкУМРЧ МКДЩРЛ ГєРЬДТ scale up ЙцНФРЛ СжЗЮ МБХУЧиОпИИ ЧпНРДЯДй. ЙЎСІДТ scale upРЛ ЧиЕЕ БйКЛРћРЮ ЙЎСІАЁ ЧиАсЕЧСі ОЪДТДйДТ АЭРдДЯДй.
1990ГтДы ШФЙн НХШя ДхФФБтОїЕщРЬ КЮЛѓЧЯИщМ ЛѓШВРЬ КЏЧЯБт НУРлЧпНРДЯДй. КЮСЗЧб РкБнРИЗЮ ОюИЖОюИЖЧб ЕЅРЬХЭИІ РњРхЧЯАэ УГИЎЧиОп ЧпДј БзЕщРК SMPРЧ БйКЛРћРЮ ЧбАшИІ ЙўОюГЊБт РЇЧи ЛѕЗЮПю ДыОШРЛ ИИЕщОњНРДЯДй. НКХфИЎСіПЁ С§СпЕШ ЕЅРЬХЭИІ КЙМіРЧ МЙіПЁ КаЛъНУХААэ, РЬ МЙіЕщРЛ ЧЯГЊРЧ ХЌЗЏНКХЭЗЮ БИМКЧи КаЛъЕШ МвЗЎРЧ ЕЅРЬХЭИІ МЙіЕщРЬ КДЗФРћРИЗЮ УГИЎЧЯДТ ЧУЗЇЦћРЛ АГЙпЧЯПЉ ЛчПыЧЯБт НУРлЧЯПДНРДЯДй. РЬЗЏЧб КаЛъ КДЗФ ОЦХАХиУФДТ ДмРЇ ЦЎЗЃРшМЧ УГИЎ МКДЩРК ЖГОюСіСіИИ ДыПыЗЎ ЕЅРЬХЭИІ РњРхЧЯАэ УГИЎЧЯДТЕЅ РжОюМДТ КёПыИщПЁМГЊ МКДЩИщПЁМ SMPКИДй ПљЕюШї ЖйОюГЕНРДЯДй. ЖЧЧб scale out ЙцНФРИЗЮ ЕЅРЬХЭ СѕАЁ Йз МКДЩ ЧтЛѓПЁЕЕ РЏПЌЧЯПДРИИч ЛѓПы ЧЯЕхПўОюИІ ШАПыЧи КёПыИщПЁМЕЕ РхСЁРЬ РжОњНРДЯДй. РЬЗЏЧб КаЛъ КДЗФ ОЦХАХиУФИІ MPP (Massive Parallel Processing) РЬЖѓАэ ЧеДЯДй.
АЁРх ХЋ ЙЎСІДТ КёПыРдДЯДй. РњРхЧиОп Чв ЕЅРЬХЭРЧ ОчРЬ ЦјЙпРћРИЗЮ ДУОюГ ЕЅДй ОюЧУИЎФЩРЬМЧРЧ МіПЭ СОЗљЕЕ ДУОюГЊ НКХфИЎСіРЧ СѕМГАњ НХБдЕЕРд КёПыРЬ IT ПЙЛъПЁМ ГЪЙЋГЊ ХЋ КёСпРЛ ТїСіЧЯАд ЕЧОњНРДЯДй. НКХфИЎСі АЁЛѓШИІ ХыЧб ОР ЧСЗЮКёСЎДз (Thin provisioning) РЛ РћПыЧи НКХфИЎСі АЁПыЗќРЛ ГєРЬДТ ЕЅПЁЕЕ ЧбАшАЁ ЙпЛ§Чв МіЙлПЁ ОјОњНРДЯДй.
ЕЮЙјТА ЙЎСІДТ МКДЩРдДЯДй. ЦЏШї ДыПыЗЎ ЕЅРЬХЭ УГИЎПЁ ПфБИЕЧДТ ГєРК ОВЗчЧВРЛ СІАјЧЯСі ИјЧпНРДЯДй. ИЙРК КёПыРЛ ЕщПЉ НКХфИЎСіПЁМКЮХЭ МЙіБюСіРЧ ЕЅРЬХЭ РќМлМгЕЕИІ ЧтЛѓНУХААэРк SAN, Infiniband Ею ДйОчЧб АэМг НКХфИЎСі ГзЦЎПіХЉИІ РћПыЧЯАэ НКХфИЎСі РкУМ I/O МКДЩРЛ ГєРЬДѕЖѓЕЕ, АсБЙ ДыПыЗЎ ЕЅРЬХЭАЁ Чб АїПЁ ИєЗС НКХфИЎСі ПЕПЊРЬ КДИёРЬ ЕЧДТ БйКЛРћРЮ ЙЎСІСЁРЛ ОШАэ РжОњНРДЯДй.
РЬУГЗГ КЙМіРЧ ОюЧУИЎФЩРЬМЧ МЙіЕщРЬ ХыЧе НКХфИЎСі ЗЙРЬОюПЁ ЕЅРЬХЭИІ РњРхЧЯДТ БИСЖИІ SMP (Symmetric Multi-Processing) РЬЖѓАэ ЧеДЯДй. SMP БИСЖПЁМДТ ЕЅРЬХЭ ПыЗЎРЬГЊ МКДЩ ЧтЛѓРЛ РЇЧиМДТ РхКё РкУМРЧ МКДЩРЛ ГєРЬДТ scale up ЙцНФРЛ СжЗЮ МБХУЧиОпИИ ЧпНРДЯДй. ЙЎСІДТ scale upРЛ ЧиЕЕ БйКЛРћРЮ ЙЎСІАЁ ЧиАсЕЧСі ОЪДТДйДТ АЭРдДЯДй.
1990ГтДы ШФЙн НХШя ДхФФБтОїЕщРЬ КЮЛѓЧЯИщМ ЛѓШВРЬ КЏЧЯБт НУРлЧпНРДЯДй. КЮСЗЧб РкБнРИЗЮ ОюИЖОюИЖЧб ЕЅРЬХЭИІ РњРхЧЯАэ УГИЎЧиОп ЧпДј БзЕщРК SMPРЧ БйКЛРћРЮ ЧбАшИІ ЙўОюГЊБт РЇЧи ЛѕЗЮПю ДыОШРЛ ИИЕщОњНРДЯДй. НКХфИЎСіПЁ С§СпЕШ ЕЅРЬХЭИІ КЙМіРЧ МЙіПЁ КаЛъНУХААэ, РЬ МЙіЕщРЛ ЧЯГЊРЧ ХЌЗЏНКХЭЗЮ БИМКЧи КаЛъЕШ МвЗЎРЧ ЕЅРЬХЭИІ МЙіЕщРЬ КДЗФРћРИЗЮ УГИЎЧЯДТ ЧУЗЇЦћРЛ АГЙпЧЯПЉ ЛчПыЧЯБт НУРлЧЯПДНРДЯДй. РЬЗЏЧб КаЛъ КДЗФ ОЦХАХиУФДТ ДмРЇ ЦЎЗЃРшМЧ УГИЎ МКДЩРК ЖГОюСіСіИИ ДыПыЗЎ ЕЅРЬХЭИІ РњРхЧЯАэ УГИЎЧЯДТЕЅ РжОюМДТ КёПыИщПЁМГЊ МКДЩИщПЁМ SMPКИДй ПљЕюШї ЖйОюГЕНРДЯДй. ЖЧЧб scale out ЙцНФРИЗЮ ЕЅРЬХЭ СѕАЁ Йз МКДЩ ЧтЛѓПЁЕЕ РЏПЌЧЯПДРИИч ЛѓПы ЧЯЕхПўОюИІ ШАПыЧи КёПыИщПЁМЕЕ РхСЁРЬ РжОњНРДЯДй. РЬЗЏЧб КаЛъ КДЗФ ОЦХАХиУФИІ MPP (Massive Parallel Processing) РЬЖѓАэ ЧеДЯДй.
MPP РќМКНУДы
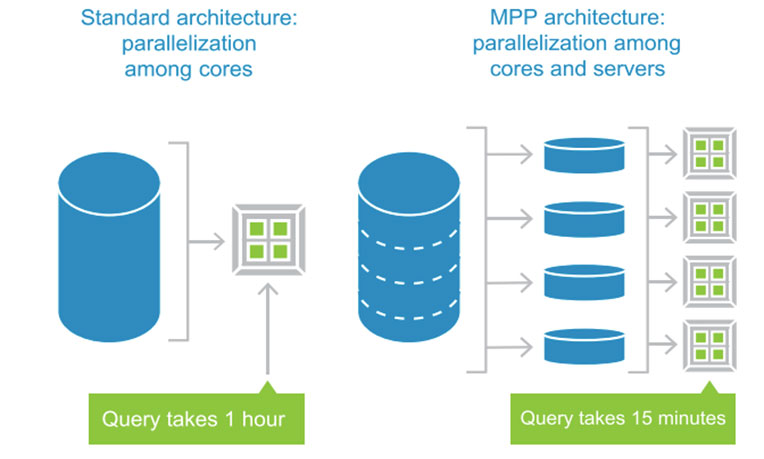
КђЕЅРЬХЭ НУДыРЧ ЕЅРЬХЭ НУНКХлПЁМ MPP ОЦХАХиУФ БтЙнРЧ ЕЅРЬХЭ РњРхМвДТ ЛчНЧЛѓ ЧЅСиРЬ ЕЧОњНРДЯДй. ДмМјШї ЕЅРЬХЭ РњРхРЧ КёПы ШПРВМК УјИщПЁМИИРЬ ОЦДЯЖѓ ДыПыЗЎ ЕЅРЬХЭПЁ ДыЧб СњРЧ МКДЩ ПЊНУ MPPАЁ SMPПЁ КёЧи ПљЕюЧеДЯДй. Пж БзЗВБюПф? ПЙИІ ЕщОю, 10БЧТЅИЎ ЙщАњЛчРќПЁМ ЁЎЕЅРЬХЭЁЏ ЖѓДТ ДмОюАЁ Уб Ию Йј ЕюРхЧЯДТАЁИІ АшЛъЧЯДТ РлОїРЬ РжДйАэ ЧеНУДй. Чб ИэРЧ ДЋАњ МеРЬ ОЦСж КќИЅ ЙкЛчБо РЮРчПЭ П ИэРЧ ЦђЙќЧб СпЧаЛ§ЕщРЬ РЬ РлОїРЛ ЕПНУПЁ НУРлЧЯИщ ОюДР ТЪРЬ Дѕ КќИЃАэ СЄШЎЧЯАд АсАњИІ ГЛОю ГѕРЛБюПф? Чб ИэРЧ ЙкЛчДТ ЙщАњЛчРќ 10БЧРЛ И№ЕЮ ШШОюОп ЧЯАэ, СпЧаЛ§ЕщРК Чб Иэ Дч Чб БЧОП ШШОю АЂАЂРЧ АсАњИІ УыЧеЧЯИщ ЕЫДЯДй. СІ ОЦЙЋИЎ Чб ИэРЧ ЙкЛчРЧ СіДЩРЬ ГєАэ РЯУГИЎАЁ КќИЃДй ЧЯДѕЖѓЕЕ АсАњДТ ДчПЌШї П ИэРЧ СпЧаЛ§РЧ НТИЎРдДЯДй. ЕПРЯЧб ПјИЎЗЮ MPPДТ SMPПЁ КёЧи ДыПыЗЎ ЕЅРЬХЭ УГИЎРЧ РЯА§ УГИЎПЁ РжОю ПљЕюШї ЖйОюГГДЯДй.
SSOTПЭ MVOT
MPP БтЙн ЕЅРЬХЭ РњРхМвИІ ШЎКИЧбДйАэ ЧиМ И№Еч АЭРЬ ЧиАсЕЧДТ АЭРЬ ОЦДеДЯДй. ЕЅРЬХЭ РњРхРЬЖѓДТ ДмАшПЁМ ЕЅРЬХЭИІ КёПы ШПРВРћРИЗЮ РњРхЧбДйДТ АЭРК ГЪЙЋГЊ ДчПЌЧб РЬОпБтРЬРк ЛчНЧ АэЙЮРЧ ДыЛѓСЖТї ЕЧСі ИјЧеДЯДй. СЄИЛ СпПфЧб АњСІДТ ОюЖВ ЕЅРЬХЭИІ ОюДР РЇФЁПЁ ОюЖЛАд РњРхЧЯПЉ ЕЅРЬХЭРЧ АэИГАњ СпКЙРЛ УжМвШЧЯАэ, ЕЅРЬХЭРЧ СЄЧеМКРЛ РЏСіЧЯИч, ДйПюНКЦЎИВ РЏРњЕщРЧ КаМЎ ПфАЧРЛ ИИСЗНУХГ АЭРЮАЁРдДЯДй. ЙАЗа РЬ АњСІДТ ЕЅРЬХЭ РњРх ДмАшПЁМИИ АэЙЮЧиОп Чв ЙЎСІАЁ ОЦДЯЖѓ ЕЅРЬХЭ ПЃСіДЯОюИЕ РќЙнПЁ АЩУФ АэЙЮЧиОп Чв Чб СЖСїРЧ ЕЅРЬХЭ РќЗЋРЬСіИИ, ЕЅРЬХЭ РњРхАњ АќЗУЕШ ПфМвАЁ АЁРх ХЉАд ПЕЧтРЛ ЙЬФЁЙЧЗЮ ПЉБтМ О№БоЧЯАэРк ЧеДЯДй.
ЕЅРЬХЭРЧ РњРх РќЗЋРЛ Чб ИЖЕ№ЗЮ СЄРЧЧЯИщ ЕЮ АЁСі ЛѓУцЧЯДТ ПфАЧРЧ БеЧќСЁРЛ УЃДТ АЭРдДЯДй. ПЉБтМ ЕЮ АЁСі ЛѓУцЧЯДТ ПфАЧЕщРЬ ЙйЗЮ SSOT (Single Source of Truth) ПЭ MVOT (Multiple Versions of Truth) РдДЯДй. SSOTЖѕ СЖСї ГЛ ЕЅРЬХЭ РкПјПЁ ДыЧб РЯА§РћРЬАэ АЗТЧб ХыСІИІ ХыЧи СЄЧеМК, ХыРЯМК, КИОШРЛ ШЎКИЧи РпИјЕШ ЕЅРЬХЭАЁ РЏХыЕЧДТ АЭРЛ ЙцСіЧЯАэРк ЧЯГЊРЧ ЕЅРЬХЭ ПјКЛРЛ РњРхЧЯДТ ЙцНФРдДЯДй. MVOTЖѕ РЬПЭ ЙнДыЗЮ ДйОчЧб КЮМРЧ ДйОчЧб ЛѓШВАњ ЕЅРЬХЭ ПфАЧРЛ ИИСЗНУХАБт РЇЧи ЕЅРЬХЭКЃРЬНКИІ КаЛъНУФб ЧЪПфПЁ ЕћЖѓ ПЉЗЏ КЛРЧ ЕЅРЬХЭИІ РњРхЧЯДТ ЙцНФРдДЯДй. НБАд КёРЏЧЯРкИщ ЕЅРЬХЭ ПўОюЧЯПьНКДТ SSOT, ЕЅРЬХЭ ИЖЦЎДТ MVOTЖѓАэ Чв Мі РжНРДЯДй.
РЬПЁ ДыЧб ДыОШРИЗЮ ЕюРхЧб АГГфЕщРЬ EDW (Enterprise Data Warehouse) ПЭ ЕЅРЬХЭ ЗЙРЬХЉ (Data Lake) РдДЯДй. EDWПЭ ЕЅРЬХЭ ЗЙРЬХЉДТ НБАд ИЛЧи БУБиРћРЮ SSOTРдДЯДй. SSOTПЭ MVOTРЧ АцАшМБРЬ ЙЋГЪСЎ ДѕРЬЛѓ БтСИРЧ ЕЅРЬХЭ ПўОюЧЯПьНКЕщРЬ SSOTРЧ ПЊЧвРЛ МіЧрЧЯСі ИјЧЯАд ЕЧРк ОЦПЙ СЖСї ГЛ И№Еч ЕЅРЬХЭРЧ СІ 1 БтТјСіИІ ИИЕщОю SSOTИІ БИМКЧЯАэ ГЊИгСі И№Еч НУНКХлЕщРК MVOTЗЮМ РЬАїРЧ ЕЅРЬХЭИІ ТќСЖЧЯЕЕЗЯ ЧЯРкДТ АЭРЬ БтКЛЛчЛѓРдДЯДй. ПРДУГЏ КђЕЅРЬХЭ ЧУЗЇЦћРЧ ДыКЮКаРК РЬЗЏЧб ЛчЛѓПЁ ЕћЖѓ БИМКЕЧОю РжНРДЯДй. ЧЯДмРЧ AmazonРЧ ЛѓПы ХЌЖѓПьЕх БтЙн ЕЅРЬХЭ МКёНК ОЦХАХиУФИІ ТќСЖЧи КИНУБт ЙйЖјДЯДй.
ЕЅРЬХЭРЧ РњРх РќЗЋРЛ Чб ИЖЕ№ЗЮ СЄРЧЧЯИщ ЕЮ АЁСі ЛѓУцЧЯДТ ПфАЧРЧ БеЧќСЁРЛ УЃДТ АЭРдДЯДй. ПЉБтМ ЕЮ АЁСі ЛѓУцЧЯДТ ПфАЧЕщРЬ ЙйЗЮ SSOT (Single Source of Truth) ПЭ MVOT (Multiple Versions of Truth) РдДЯДй. SSOTЖѕ СЖСї ГЛ ЕЅРЬХЭ РкПјПЁ ДыЧб РЯА§РћРЬАэ АЗТЧб ХыСІИІ ХыЧи СЄЧеМК, ХыРЯМК, КИОШРЛ ШЎКИЧи РпИјЕШ ЕЅРЬХЭАЁ РЏХыЕЧДТ АЭРЛ ЙцСіЧЯАэРк ЧЯГЊРЧ ЕЅРЬХЭ ПјКЛРЛ РњРхЧЯДТ ЙцНФРдДЯДй. MVOTЖѕ РЬПЭ ЙнДыЗЮ ДйОчЧб КЮМРЧ ДйОчЧб ЛѓШВАњ ЕЅРЬХЭ ПфАЧРЛ ИИСЗНУХАБт РЇЧи ЕЅРЬХЭКЃРЬНКИІ КаЛъНУФб ЧЪПфПЁ ЕћЖѓ ПЉЗЏ КЛРЧ ЕЅРЬХЭИІ РњРхЧЯДТ ЙцНФРдДЯДй. НБАд КёРЏЧЯРкИщ ЕЅРЬХЭ ПўОюЧЯПьНКДТ SSOT, ЕЅРЬХЭ ИЖЦЎДТ MVOTЖѓАэ Чв Мі РжНРДЯДй.
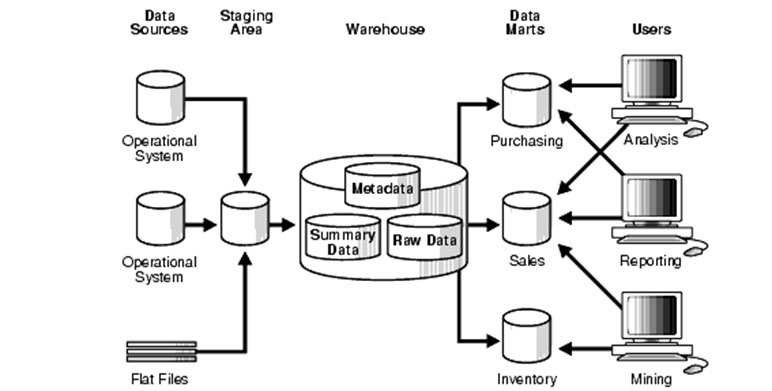
РЬПЁ ДыЧб ДыОШРИЗЮ ЕюРхЧб АГГфЕщРЬ EDW (Enterprise Data Warehouse) ПЭ ЕЅРЬХЭ ЗЙРЬХЉ (Data Lake) РдДЯДй. EDWПЭ ЕЅРЬХЭ ЗЙРЬХЉДТ НБАд ИЛЧи БУБиРћРЮ SSOTРдДЯДй. SSOTПЭ MVOTРЧ АцАшМБРЬ ЙЋГЪСЎ ДѕРЬЛѓ БтСИРЧ ЕЅРЬХЭ ПўОюЧЯПьНКЕщРЬ SSOTРЧ ПЊЧвРЛ МіЧрЧЯСі ИјЧЯАд ЕЧРк ОЦПЙ СЖСї ГЛ И№Еч ЕЅРЬХЭРЧ СІ 1 БтТјСіИІ ИИЕщОю SSOTИІ БИМКЧЯАэ ГЊИгСі И№Еч НУНКХлЕщРК MVOTЗЮМ РЬАїРЧ ЕЅРЬХЭИІ ТќСЖЧЯЕЕЗЯ ЧЯРкДТ АЭРЬ БтКЛЛчЛѓРдДЯДй. ПРДУГЏ КђЕЅРЬХЭ ЧУЗЇЦћРЧ ДыКЮКаРК РЬЗЏЧб ЛчЛѓПЁ ЕћЖѓ БИМКЕЧОю РжНРДЯДй. ЧЯДмРЧ AmazonРЧ ЛѓПы ХЌЖѓПьЕх БтЙн ЕЅРЬХЭ МКёНК ОЦХАХиУФИІ ТќСЖЧи КИНУБт ЙйЖјДЯДй.
ШЃШЏМК
И№Еч ЕЅРЬХЭ РњРхМвДТ ОїНКЦЎИВРЧ ЕЅРЬХЭ РЏРд Йз СЄСІ Хј, ДйПюНКЦЎИВРЧ ЕЅРЬХЭ КаМЎ Йз НУАЂШ Хј Ею ДйОчЧб АќЗУ ЧУЗЇЦћАњРЧ ПЌАшАЁ ЧЪМіРћРдДЯДй. БзЗИСі ОЪДйИщ БзРњ АэИГЕШ ЕЅРЬХЭ ЛчРЯЗЮПЁ КвАњЧЯАд ЕЫДЯДй. СЖСї ГЛ ЕЅРЬХЭАЁ ПјШАШї РЏХыЕЧАэ СЖЧеЕЩ ЖЇИИРЬ ЕЅРЬХЭДТ РќЗЋРћ РкПјРИЗЮМ КћРЛ ЙпЧЯЙЧЗЮ АэИГЕШ ЕЅРЬХЭ ЛчРЯЗЮДТ И№Еч ЕЅРЬХЭ НУНКХлПЁМ АЁРх АцАшЧЯАэ БтЧЧЧиОп Чв ДыЛѓРдДЯДй.
АќЗУ СІЧА : Vertica, IBM IIAS
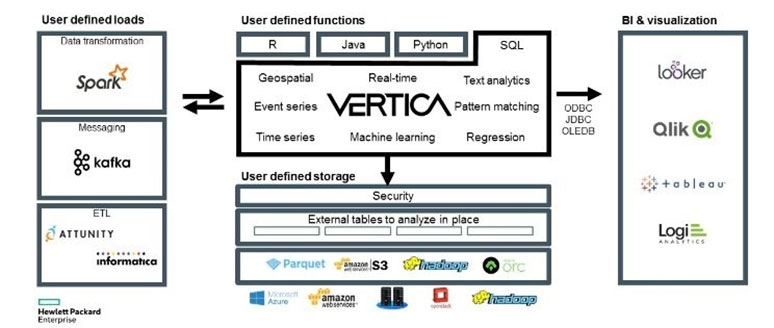
АќЗУ СІЧА : Vertica, IBM IIAS